
私は、macOS版微信にバックグラウンドでメッセージを送れるツールを作っていた。ウィンドウを出さず、マウスやキーボードを奪わず、微信の画面に切り替えず、コマンドラインで一言打つだけでメッセージが送られる。いちばん頭を悩ませたのは、「送れるかどうか」ではなく、「安定して送れるかどうか」だった。送れるときもあれば、まったく反応しないときもある。微信全体が固まってぐるぐる回ることもある。そして——最悪だったある一度——微信を起動すると「データベースが破損しています」と出た。
いろいろ試行錯誤した末に、私は送信チェーンを全面的に作り直した。今では、微信は最初から最後までどのデバッガにも触れられない。この記事では、古い方法がなぜデータベースを壊してしまうのか、新しい方法がどう回避するのかをきちんと説明する。途中で、私自身が自分の微信を壊してしまった経験についても書く。
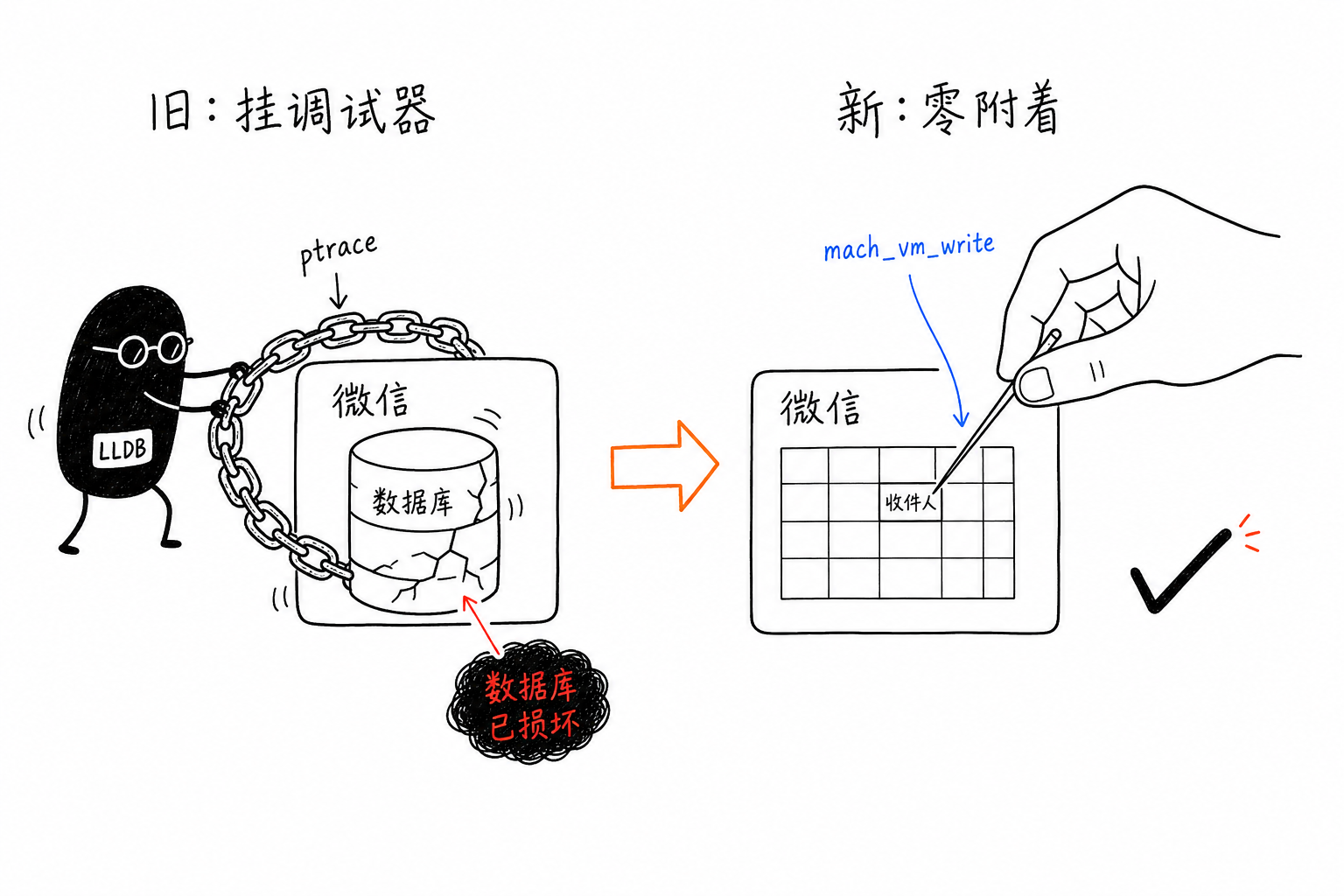
古い方法:ブレークポイントを仕掛け、正しい瞬間に1文字を書き換える
微信でメッセージを送る流れで、肝心なのはたった1ステップだ。メッセージを誰に送るかは、ある会話オブジェクト内のフィールドから読み出される。チャット欄に文字を打って Enter を押すと、微信内部ではこのフィールドを「受信者」として扱う。
古い方法はこうだった。
- LLDB を微信プロセスにアタッチし、「受信者を読む」命令のあたりにブレークポイントを置く。
- CGEvent で微信プロセスにキー入力を流し込み、送りたい文字を現在のチャット欄に打ち込む。
- 入力によってその命令が発火し、ブレークポイントに当たる。微信が停止している隙に、受信者フィールドを本当に送りたい相手へ書き換える。
- 実行を再開すると、微信は私が書き換えたフィールドを使ってメッセージを送る。
キーボードをシミュレートする部分そのものに問題はない。CGEvent は指定したプロセスへ直接投げられるので、微信が前面にいる必要もない。本当の厄介ごとは、最初のステップにあるブレークポイントだった。
ブレークポイントとは、LLDB が ptrace で微信を「つなぎ止める」ことを意味する。普段は問題なく、微信はいつも通り動く。だが ptrace にはある性質がある。デバッグ対象のプロセスはいつでも停止させられうるし、止まるタイミングは自分では制御できない。もっとも危険な組み合わせはこうだ。微信がローカルデータベースへメッセージを書き込んでいる最中に、書き込み途中で Mac がスリープする。あるいは私のデーモンプロセスが落ちる——すると微信は「データベース書き込みの途中 + デバッガに止められている」という状態に取り残される。復帰後、WCDB が整合性チェックをすると、書き込みが壊れていると判断し、そのまま「データベースが破損しています」と表示する。
これは机上の話ではない。このポップアップは数日に一度くらい出ていて、しかも私のツールを動かした後にだけ現れた。かなり長く調べて、ようやく常駐アタッチがスリープとぶつかっているのだと特定した。その後、緩和策を2つ入れた。一定時間アイドルなら自動で detach すること、そしてスリープ前に電源イベントのコールバックで先回りして detach することだ。ポップアップはかなり減ったが、アタッチという行為が残っている限り、その隙間も残り続ける。
私が欲しかったのは、根本からその隙間が存在しない仕組みだった。
発想の転換: ブレークポイントが実際にしていたことは一つだけ
この一連の流れをじっと見ているうちに、あることに気づいた。送信全体の中で、デバッガにしかできない唯一の役割は、「正しいタイミングでそのフィールドに数バイトを書き込むこと」だけだった。入力は CGEvent がやっているし、送信は微信自身がやっている。どちらもデバッガは必要ない。私がブレークポイントを仕掛けていたのは、単にメモリを書き込むタイミングを得るためだった。
なら、その「メモリを書き込む」という一手を置き換えればいい。
macOS には ptrace を通らない道がある。task_for_pid で対象プロセスの task port を取り、そこから mach_vm_write で直接そのメモリに書き込む。プロセスは止まらず、縛りつけられず、traced-stop にも入らない。これは、私がヒープスキャンで画像の平文を読むときにすでに使っていたものと同じ mach 呼び出し群だ。ただ、そのときは読むだけで、今回は書く。
まず読み取りを検証した。mach でその受信者フィールドを読むと、「filehelper」(ファイル転送助手の内部 id)が返ってきた。当時フォーカスしていたチャットそのものだ。つまり mach で読めていて、フィールド位置も合っている。
次に書き込みを検証した。同じフィールドに「filehelper」を書き戻し、読み直して反映されていることを確認した。微信の状態も正常で、落ちも固まりもしない。書き込める。しかもアタッチしていない。
もう一つ、タイミングの問題がある。mach で書き込んだ受信者は、微信のその命令が読み取りに来るまで持つのか。私は違うマーカーを書き込み、三秒待ってから読み直した。値はそのままだった——微信はこのフィールドを勝手に上書きしない。実際の送信では「Enter から微信がフィールドを読むまで」は数ミリ秒しかなく、三秒よりはるかに短い。タイミングは十分に勝てる。
ここまで来ると、もともと難しいと思っていた三つの問題はすべて消えた。新しい送信経路をゼロから作り直す必要はない。ポインタ認証と格闘する必要もない。呼び出しを主スレッドへ差し戻す方法を考える必要もない。私は古いチェーンの中にあった LLDB によるメモリ書き込みの一手を、その場で mach によるメモリ書き込みへ置き換えただけだ。
詰まった場所:ブレークポイントなしで、どうやって受信者フィールドの位置を知るのか
mach でメモリに書き込むには前提がある。どのアドレスへ書き込むのかを知っていなければならない。古いやり方では、このアドレスはブレークポイントにヒットした瞬間にレジスタから取っていた——だが今はブレークポイントを張っていない。
最初、これは硬い骨だと思った。その会話オブジェクトはヒープ上にあり、アドレスは毎回違う。位置を特定するには安定したアンカーが必要だ。静的なグローバル領域をスキャンしたが、なかった。ヒープ全体をスキャンして、それを指すポインタを探すと、九十個以上の参照が出てきた。だがそのうちどれが「現在の会話マネージャ」で、フォーカスに追従して変わるスロットなのか、見分けがつかない。
見分けるには、対照実験をする必要がある。フォーカスをチャット A に置いた状態で一組記録し、チャット B に切り替えてもう一組記録する。値が変わったそのスロットこそがマネージャだ。フォーカスの切り替えは微信の画面を操作するしかないが、私は微信 UI に触らないという厳格なルールを自分に課していた。だからここだけは、人間にクリックしてもらう必要があった。
人に頼んで微信内でチャットを一つ手動で切り替えてもらい、それから九十個以上のアドレスを読み直した——一つも変わっていなかった。
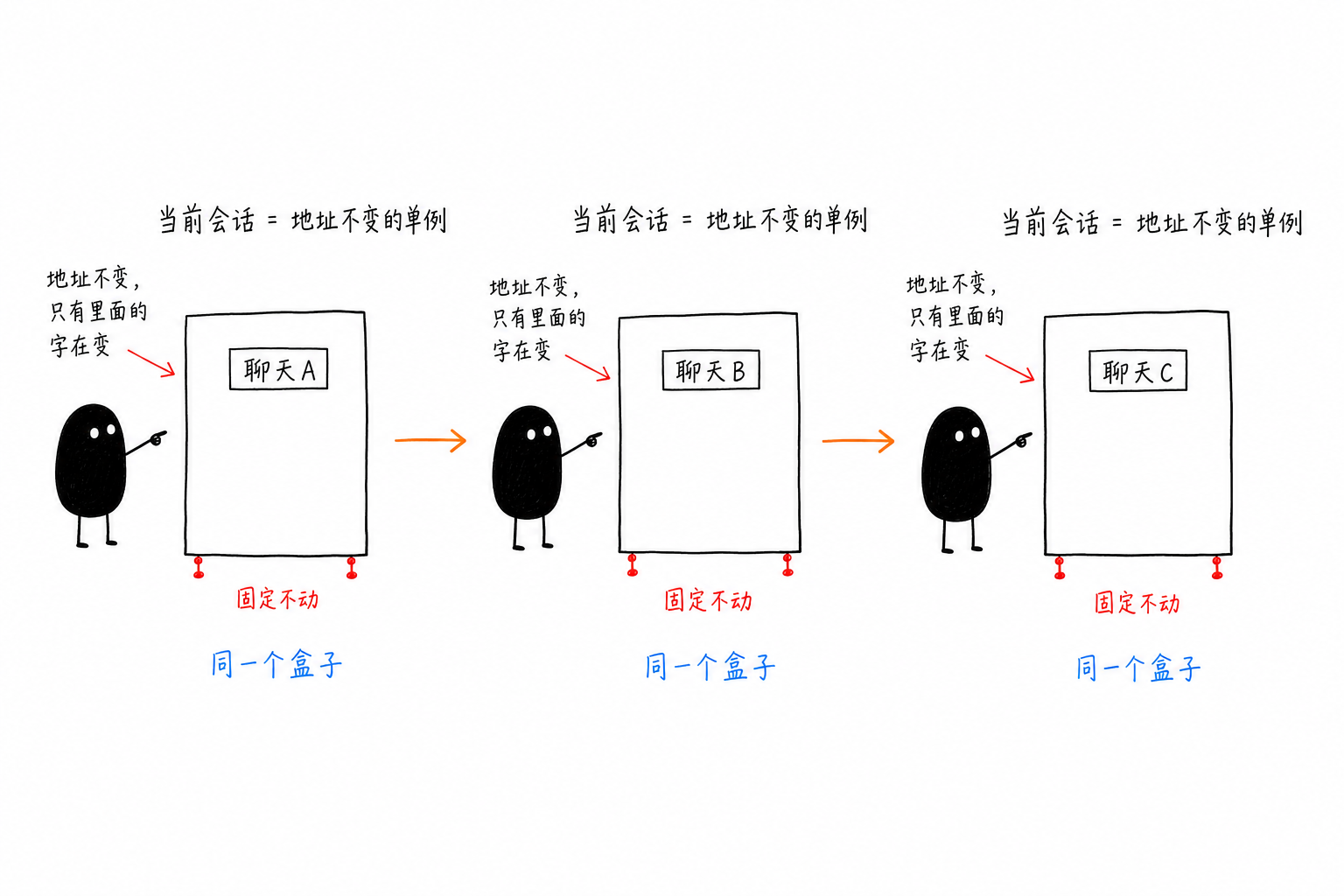
それがかえって気づきを与えてくれた。私はずっと「変わるポインタ」を探していた。だが、もし会話オブジェクト自体のアドレスが変わらないのだとしたら? その受信者フィールドを読みに行くと、以前は filehelper だったものが、チャット切り替え後には新しいチャットの id になっていた。オブジェクトのアドレスは動かず、中のそのフィールドだけがその場で書き換えられていた。
つまり、「現在フォーカスされている会話」は、アドレス固定のシングルトンオブジェクトだ。微信内でいくら切り替えても、このオブジェクトはずっとそこにあり、変わるのは内部の受信者フィールドだけ。変化するポインタを追跡する必要も、マネージャのアンカーを探す必要もまったくない——この安定したアドレスを記録しておけば十分だった。
新しい方法: 一度だけ種をまき、その後は最後までアタッチしない
最終的な方針はこうだ。
- 微信を起動するたびに、最初の 1 通だけは従来どおりにする——LLDB でブレークポイントを張って一度送信し、ついでにその安定した会話アドレスをキャッシュへ記録する。ただし、この 1 通が本当に DB に落ち、検証に通るまでは、そのアドレスを信用しない。
- アドレスを記録したら、すぐに detach する。以後、微信は ptrace から切り離される。
- その後の各メッセージは、すべて mach 経由で行う。キャッシュ済みアドレスに受信者を書き込み、CGEvent で文字を入力して Enter を押し、送信する。全工程で、微信に触れるデバッガは一切ない。
- もしキャッシュが無効になった場合、つまりアドレスを読んでみて不正だった場合は、自動で破棄し、もう一度だけ従来ルートをやり直す。LLDB は常にフォールバックであり、新ルートで問題が起きても、メッセージを黙って捨てることは絶対にない。
実際に動かすとこうなる。最初のメッセージだけブレークポイントにヒットし、DB 書き込みを検証してから detach する。微信はもうデバッグされていない。その後のメッセージでは、ブレークポイントは一度もヒットしない。微信プロセスは最初から最後まで通常の実行状態のままで、メッセージも通常どおり DB に落ちる。あの「データベースが破損しています」と出る常駐アタッチのウィンドウは、消えた。
私が自分の手で微信を落としたあの一回
改造中にひとつやらかした。これは切り出して書いておく価値がある。
そのとき私は、新しいバイナリに差し替えるためにデーモンを再起動しようとしていて、ついでに pkill で強制終了した。デーモンの下には LLDB がぶら下がっていて、その LLDB は微信にアタッチ中だった。kill -9 は後始末の機会を一切与えない。強制終了された LLDB はきれいに detach する暇がなかった——そして ptrace には致命的なルールがある。アタッチ中のデバッガを強制終了すると、それにデバッグされているプロセスも一緒に死ぬ。微信はその場で消えた。
これはまさに、この文章全体で根治しようとしていた ptrace リスクそのものだった。ただし今回はスリープで発火したのではなく、私自身の手癖の悪さで発火させた。
復旧できたのは二つのおかげだ。微信のローカルライブラリは SQLite の WAL モードで動いている。WAL 自体がクラッシュを前提に設計されていて、再起動時にログをリプレイし、書き終わっていないトランザクションを補ってくれる。私は open で微信をバックグラウンドから起動し直した。データベースは正常に読め、本当に壊れてはいなかった。
教訓は骨身に染みた。デーモンを再起動するときは、必ずきれいな終了シグナルだけを送ること。先に detach する機会を与えるためだ。絶対に kill -9 してはいけない。きれいなシグナルなら最悪でも微信が少し固まるだけで、復旧できる。-9 は即死させる。これは「微信を強制終了してはいけない」というルールの変形にすぎない——私は微信を直接殺したわけではない。微信にぶら下がっていたデバッガを殺した。そして結果は同じだった。
あと一つだけ足りない、しかし根は断てた
今は微信を起動するたびに、まだ LLDB で一発流してあのアドレスを播種する必要がある。その後は全行程 mach でいける。「最初の一発からゼロアタッチ」を実現するには、アタッチせずにフォーカス中の会話アドレスを特定できるアンカーを、さらに逆解析で見つける必要がある——おそらくハードウェア watchpoint で、微信が現在のチャットを設定する書き込み命令を捕まえることになる。これは後の話で、やってもやらなくてもいい。
だが定常状態はすでに達成できた。大多数のメッセージは mach を通り、微信はどのデバッガにも触られず、あの「データベースが破損しています」と出るウィンドウは根元から消えた。本来なら「デバッガをぶら下げる + 正しい瞬間にメモリを書き換える」に頼る必要があった送信チェーンは、「安定したアドレスを覚える + そこへ数バイト書く + キーボードをシミュレートする」へと分解された。そして、そのバイトを書き込む一手は、もはや微信を ptrace に縛りつける必要がない。
振り返ると、本当に問題を解いたのは特定の mach 呼び出しではなく、あの「ブレークポイントはいったい何をしていたのか」という一言だった。それを「デバッガが必要だ」から「正しい瞬間に数バイトを書き込む必要がある」へと縮約できた時点で、その先の道はただのエンジニアリングになった。
 微信
微信 支付宝
支付宝
コメント
コメントは即時公開されますが、ポリシー違反時は非表示になる場合があります。