
I was building a tool that could send messages through WeChat for macOS in the background: no pop-up windows, no stealing the mouse or keyboard, no switching to the WeChat interface. One command-line invocation, and the message would be sent. The hardest part was not “can it send?” but “can it send reliably?” Sometimes the message went out, sometimes nothing happened, sometimes WeChat froze with a spinning indicator, and sometimes—the worst time of all—WeChat started up and showed a “database is corrupted” warning.
After all the tinkering, I eventually rewrote the entire sending chain. Now WeChat is never touched by any debugger at any point. This article explains why the old approach could corrupt the database, how the new approach avoids that, and the time I personally brought down my own WeChat.
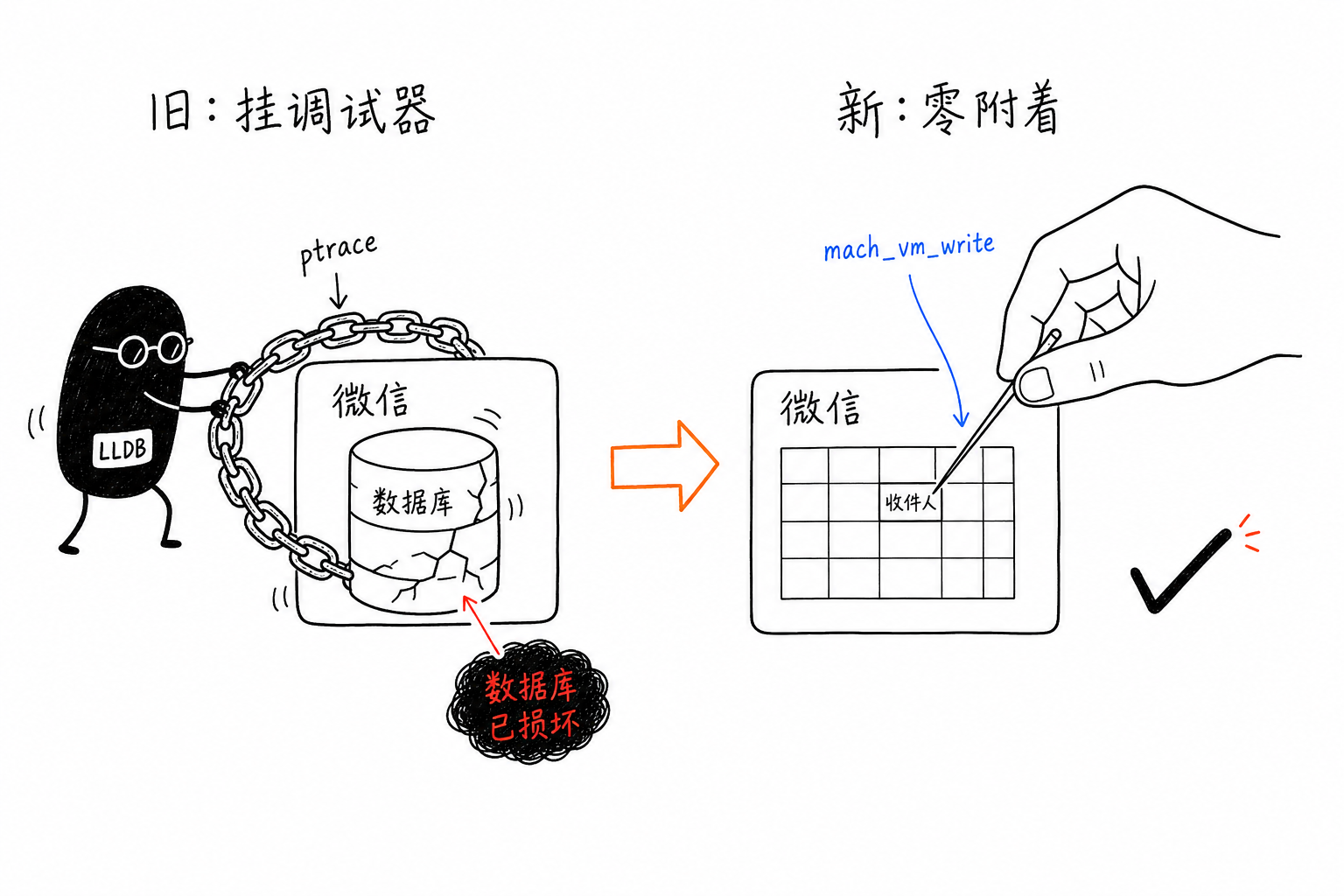
The Old Method: Set a Breakpoint and Change One Word at the Right Moment
There is one key step in WeChat’s message-sending path: who the message should be sent to is read from a field on a conversation object. When you type into the chat box and press Enter, WeChat treats this field internally as the “recipient.”
The old method worked like this:
- Attach LLDB to the WeChat process and set a breakpoint on the instruction that “reads the recipient”;
- Use CGEvent to inject keystrokes into the WeChat process, typing the text to send into the current chat box;
- Typing triggers that instruction, the breakpoint hits, and while WeChat is paused, I rewrite the recipient field to the person I actually want to send to;
- Resume execution, and WeChat sends the message using the field I modified.
The keyboard simulation step itself was fine. CGEvent can deliver events directly to a specified process, so WeChat does not need to be in the foreground. The real trouble was the breakpoint in step one.
A breakpoint means LLDB uses ptrace to “leash” WeChat. Most of the time, nothing happens and WeChat runs normally. But ptrace has one property: the debugged process may be stopped at any time, and you do not control when it stops. The most dangerous combination is this: WeChat is writing a message to its local database, the write is halfway through, and then the Mac goes to sleep, or my daemon crashes—leaving WeChat stuck in the state of “mid-database-write + stopped by debugger.” When it wakes up, WCDB runs an integrity check, finds the database corrupted, and immediately shows a “database corrupted” alert.
This was not theoretical. That alert appeared roughly every few days, only after my tool had been running. It took a long time to trace it back to persistent attachment colliding with sleep. Later, I added two mitigations: automatically detach after a period of idleness, and proactively detach before sleep via a power-event callback. The alerts became much rarer, but as long as attachment still existed, that window of risk still existed.
What I wanted was to eliminate that window at the root.
Shift in Thinking: The Breakpoint Was Only Doing One Thing
After staring at this chain for long enough, I realized something: in the entire send flow, the debugger’s only irreplaceable role was “writing a few bytes into that field at the right moment.” Typing was handled by CGEvent, sending was handled by WeChat itself, and neither required the debugger. The only reason I was setting a breakpoint was to get a timing opportunity to write memory.
So I just needed to replace that one “write memory” step.
On macOS, there is a path that does not go through ptrace: use task_for_pid to obtain the target process’s task port, then use mach_vm_write to write directly into its memory. The process does not stop, does not get tethered, and does not enter a traced-stop. This was exactly the same set of Mach calls I was already using when heap-scanning to read plaintext images; back then it was read-only, and now it needed to write.
First, I verified reading: I used Mach to read that recipient field, and what came back was filehelper (the internal ID for File Transfer Assistant), which was exactly the chat focused at the time. That proved Mach could read it, and that the field location was correct.
Then I verified writing: I wrote filehelper back into the same field, read it back to confirm it landed, and WeChat stayed normal—no crash, no freeze. The write worked, and without attaching.
There was also a timing question: could the recipient I wrote via Mach survive until WeChat’s instruction came along to read it? I wrote in a different marker, waited three seconds, then read it back. The value was unchanged—WeChat would not overwrite this field on its own. In the real send flow, there are only a few milliseconds between “press Enter” and “WeChat reads the field,” far shorter than three seconds. The timing was completely safe.
At this point, the three problems I had thought would be hard all disappeared: no need to rebuild a new send path from scratch, no need to deal with pointer authentication, and no need to find a way to inject a call back onto the main thread. I had simply replaced the LLDB memory write inside the old chain, in place, with a Mach memory write.
Where I Got Stuck: Without a Breakpoint, How Do You Know Where the Recipient Field Is?
Mach memory writing has one prerequisite: you have to know which address to write to. In the old approach, that address was grabbed from a register when the breakpoint hit—but now I wasn’t setting a breakpoint.
At first, I thought this would be a tough nut to crack. That conversation object lives on the heap, and its address is different every time, so I needed some stable anchor to locate it. I scanned the static global region: nothing. I scanned the entire heap for pointers to it and found more than ninety references, but I couldn’t tell which one was the “current conversation manager” slot that changes with focus.
To distinguish them, I needed a control experiment: record one set while the focus is on chat A, switch to chat B, then record another set. The slot whose value changed would be the manager. Switching focus can only be done through the WeChat interface, and the hard rule I had set for myself was not to touch the WeChat UI, so this part had to be done by a real person.
I asked someone to manually switch chats in WeChat, then reread those ninety-plus addresses—not a single one had changed.
That was what woke me up. I had been looking for a “pointer that changes,” but what if the conversation object’s own address didn’t change? I read the recipient field: it had previously been filehelper, and after switching chats it became the new chat’s ID. The object address hadn’t moved; only that field inside it had been overwritten in place.
In other words, the “currently focused conversation” is a singleton object with a fixed address. As you switch around in WeChat, that object stays right where it is; only its internal recipient field changes. I didn’t need to track any changing pointer at all, and I didn’t need to find a manager anchor—recording this stable address was enough.
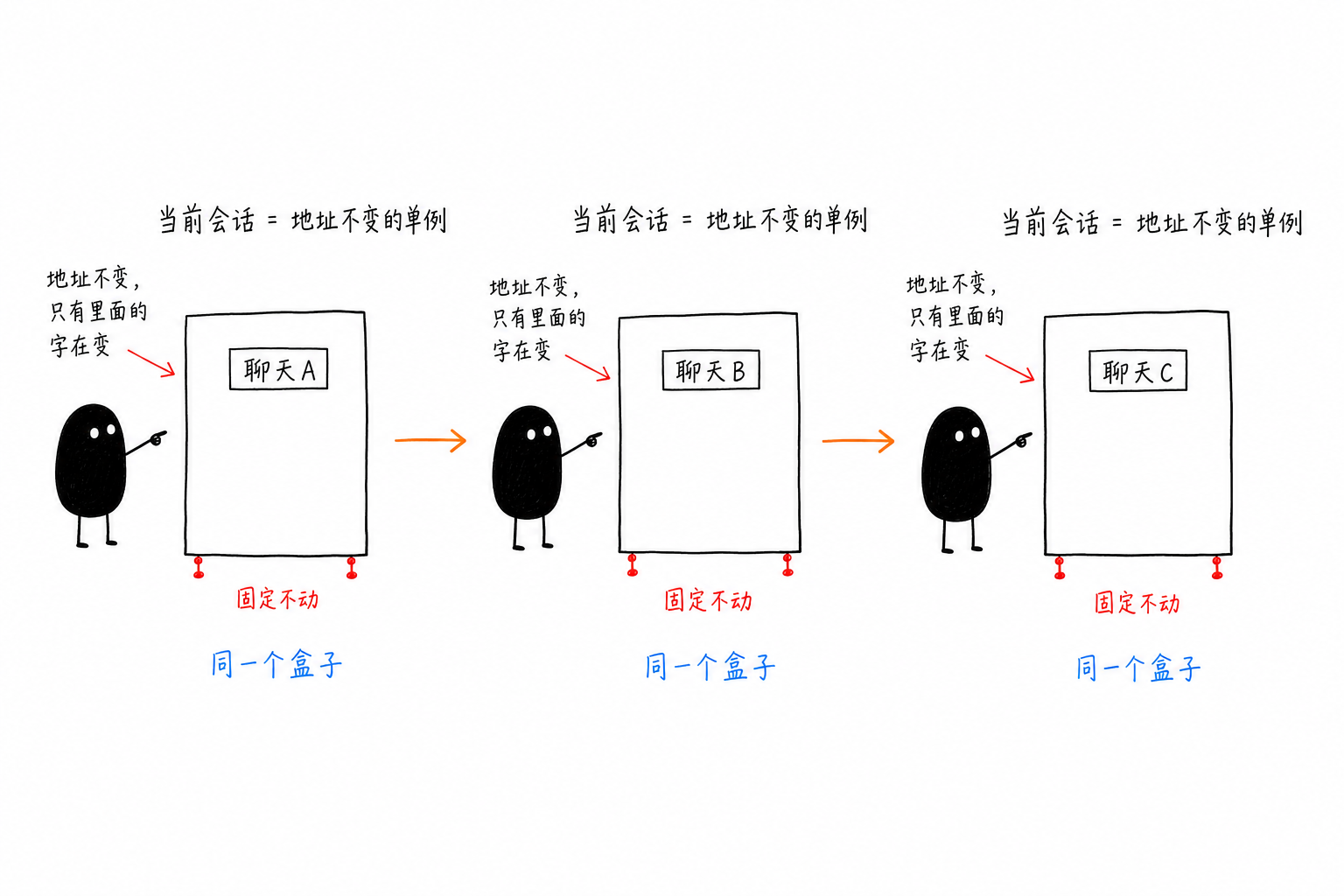
New Approach: Seed Once, Then Stay Unattached
The final plan worked like this:
- After each WeChat launch, the first message still takes the old path: LLDB hits the breakpoint once, and I record that stable conversation address into the cache. But I only trust the address after that message has truly been written to the database and verified;
- Once the address is recorded, detach immediately. From then on, WeChat is free from
ptrace; - Every message after that goes through Mach: write the recipient into the cached address, type and press Enter with
CGEvent, and send it out. No debugger touches WeChat at any point; - If the cache ever goes stale, meaning the address no longer reads correctly, invalidate it automatically and fall back to the old path once. LLDB is always the safety net; a problem in the new path will never silently drop a message.
What it looked like in practice: the first message hit the breakpoint, passed database verification, and detached; WeChat was no longer being debugged. For all later messages, the breakpoint was never hit again, the WeChat process stayed in a normal running state the whole time, and messages were written to the database as usual. That persistent attached-debugger window that used to trigger “Database corrupted” was gone.
The Time I Killed WeChat With My Own Hands
I tripped over something during the refactor, and it’s worth calling out separately.
At the time, I needed to restart the daemon to swap in a new binary, so I casually used pkill to force-kill it. The daemon had an LLDB child process, and that LLDB was attached to WeChat. kill -9 gives a process no chance to clean up, so the force-killed LLDB never got to detach cleanly—and ptrace has a fatal rule: if you force-kill an attached debugger, the process being debugged dies with it. WeChat disappeared on the spot.
That was exactly the ptrace risk I was trying to eliminate in this whole piece, except this time it wasn’t triggered by sleep; it was triggered by my own itchy fingers.
Recovery came down to two things: WeChat’s local database uses SQLite WAL mode, and WAL is designed for crashes—on restart, it replays the log to finish incomplete transactions; then I used open to launch WeChat again in the background, and the database could be read normally. It wasn’t actually corrupted.
I burned the lesson into memory: restarting the daemon must only be done with a clean exit signal, giving it a chance to detach first. Never use kill -9. A clean signal, at worst, makes WeChat hang briefly, which is recoverable; -9 goes straight for the throat. This is a variant of the same rule as “never force-kill WeChat”—I didn’t kill WeChat directly, but I killed the debugger attached to it, and the result was the same.
The Last Piece Is Still Missing, but the Root Has Been Cut
Right now, every WeChat launch still needs one LLDB command to seed that address; after that, it’s mach all the way. To get to “zero attachment even for the first command,” I’d need to reverse one more anchor that can locate the focused-conversation address without attaching—most likely by using a hardware watchpoint to catch the write instruction where WeChat sets the current chat. That’s for later; maybe worth doing, maybe not.
But the steady state is already there: the vast majority of messages go through mach, WeChat is never touched by any debugger, and the window that pops up saying “database corrupted” disappears at the root. A sending chain that originally depended on “attach a debugger + modify memory at the right moment” has been broken down into “remember a stable address + write a few bytes into it + simulate the keyboard,” and that byte write no longer requires tying WeChat to ptrace.
Looking back, the real solution wasn’t any particular mach call, but the question: “what exactly did the breakpoint do?” Once it was reduced from “I need a debugger” to “I need to write a few bytes at the right moment,” everything after that was just engineering.
 微信
微信 支付宝
支付宝
Comments
Replies are public immediately and may be moderated for policy violations.