
Anyone doing browser automation will eventually fall into the same trap: trying every possible way to disguise an automated browser as a real human, getting spotted by a website at a glance, adding another layer of disguise, and getting spotted again. I only made sense of this after I figured out what the detection side is actually checking.
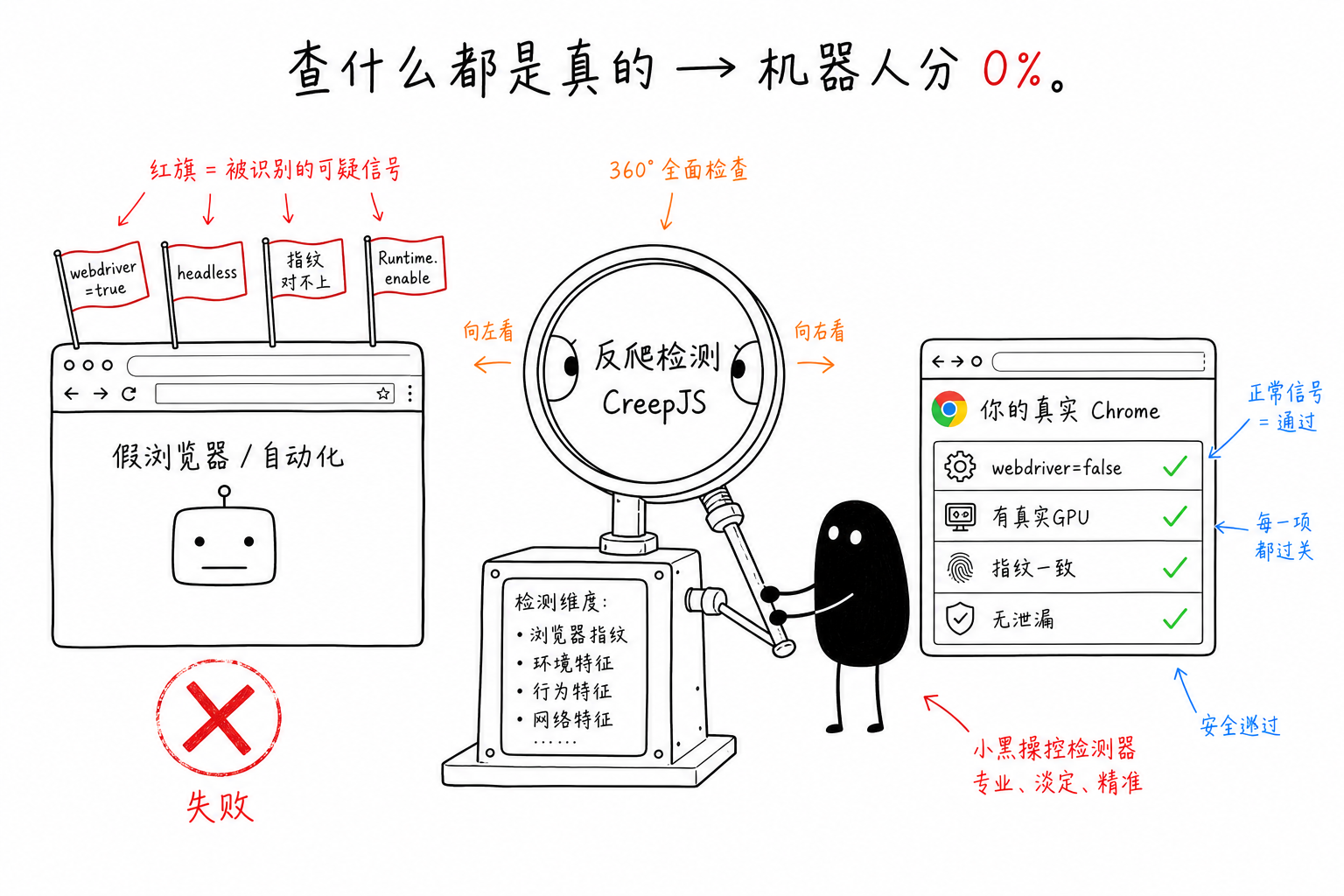
Let me start with a counterintuitive conclusion: detectors like CreepJS do not directly decide whether you are a bot. They do something else instead: collect dozens of signals exposed by your browser, then reconcile them against one another to see where things do not line up. Every mismatch is recorded as a "lie." The more lies, the lower the score. Internally, it literally calls these lies.
Once you change the perspective, a lot of things start making sense.
What a Real Browser Looks Like
I had chrome-use connect to the Chrome instance already open on this Mac and read a few of the signals most commonly checked:
{
"webdriver": false,
"gpu": "ANGLE (Apple, ANGLE Metal Renderer: Apple M3, Unspecified Version)",
"plugins": 5,
"languages": "en,en-US,ja",
"timeZone": "Asia/Tokyo"
}
It looks completely ordinary, but every item is something detectors pay attention to:
navigator.webdriver is false. The W3C WebDriver specification says that when a browser is controlled by automation, this getter returns true; Selenium, Puppeteer, and Playwright all default to true. In my case it is false because no framework is actually driving it. I am using it myself.
The GPU string, Apple M3, is the real graphics card name obtained through WebGL's WEBGL_debug_renderer_info extension. Headless Chrome has no real GPU, so this field is usually SwiftShader or llvmpipe, meaning software rendering. Software rendering is not inherently forbidden, but when it appears next to a browser that claims to be a normal Mac, it becomes a contradiction.
There are 5 plugins, the time zone is Asia/Tokyo, and the language list includes ja. These small signals mean little on their own. Their value lies in whether they line up.
The Killer Move Is Cross-Checking
When an automated browser tries to disguise itself, it usually changes surface-level things: modifying the UA to claim it is a Mac, changing navigator.webdriver, injecting scripts to cover up headless traces. But while you can change the UA, you cannot change the long chain of related signals that should move with it.
The UA says macOS, but WebGL reports llvmpipe, which is typical Linux software rendering. That does not line up. It claims the time zone is Tokyo, but the exit IP is in Frankfurt. That does not line up. The screen resolution is manually changed, but devicePixelRatio and the dimensions actually rendered by Canvas do not line up. CreepJS checks these signals against one another, and every contradiction counts as a lie.
So the real difficulty of disguise has never been "cover up one specific item." It is that after covering up that item, it still has to remain consistent with dozens of others. Change one thing and you leak a whole chain. This is the natural disadvantage of disguise.
The Hardest Trace to Hide Is Not in the JS Layer
The signals above are all still readable from JS, so in theory they can all be hooked. But some traces live lower down.
When you drive a browser with the Chrome DevTools Protocol, once Runtime.enable is sent, which many CDP libraries do by default, Chrome starts reporting execution contexts and console calls outward through the protocol. rebrowser's detector uses exactly this point: it constructs an object with a getter and calls console.debug on it. As long as Runtime.enable is on, CDP has to serialize this object and send it out. Serialization triggers the getter; once the getter fires, the page immediately knows that "a debugger with Runtime.enable turned on is attached to me."
What makes this painful is that it is not some property in your JS that you can hook away. It is a trace left by the driving method you chose. The rebrowser panel has a dedicated runtimeEnableLeak item, and plenty of so-called stealth solutions fail right there.
Why Real Browsers Are Easier
Look back at the opening signals: a real Chrome's webdriver is naturally false, its GPU is naturally Apple M3, and its time zone, languages, and Canvas all come from the same real machine, so they are consistent everywhere. There are no lies to count. chrome-use connects through a browser extension plus native messaging, does not open --remote-debugging-port, and the relay path does not enable Runtime.enable by default, so even that protocol-layer trace is absent.
This is not "good disguise." There is simply nothing to disguise.
There is another layer that is easy to overlook: patching itself leaves traces. The code you use to hook navigator.webdriver changes the property's descriptor and changes the return value of toString. The detector can simply check whether this property has been tampered with. The more you patch, the more places can be identified as modified. A real browser does not carry this burden, because it has not been patched.
Run the Comparison Yourself
Do not take my word for it. The most direct way is to run both browsers once:
- CreepJS: look at its trust score and the specific lies it lists.
- rebrowser-bot-detector: focus on
runtimeEnableLeakandnavigatorWebdriver.
Run an ordinary headless automation setup once, then run the browser you use every day once, and put the two lies lists side by side. I will not need to explain the difference. If you really need to handle tasks that "only real humans can pass," such as logged-in sessions or risk-control-sensitive operations, using a browser with no lies to reconcile saves far more trouble than relying on a fake browser that barely holds together through endless patching.
 微信
微信 支付宝
支付宝
Comments
Replies are public immediately and may be moderated for policy violations.