
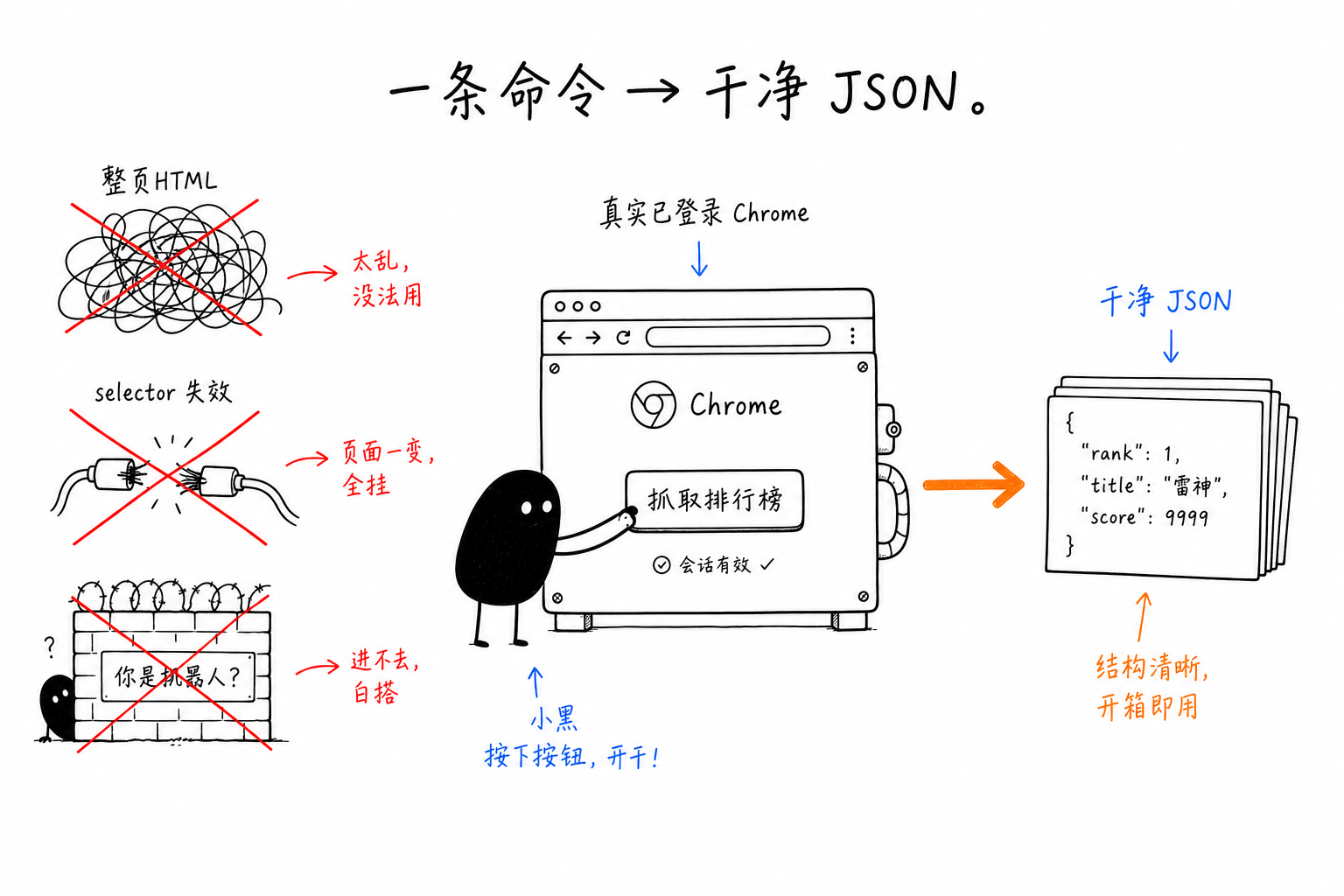
agentにWebページのデータを取らせるために、私は前後して3つの不器用な方法を試した。
いちばん直接的なのは、ページ全体のHTMLをモデルに渡して自分で読ませることだ。中くらいのページでも数万tokenになり、データをまだ取れていないのに、コンテキストを先に半分ほど使い切ってしまう。モデルもよく行を取り違える。2つ目はCSSセレクターを自分で書き、1フィールドごとにfindを1回、さらにgetを1回するやり方だ。10個を超えるフィールドなら10回を超える往復になり、遅くて冗長だ。3つ目はJSのevalを手書きしてページに流し込んで実行すること。使えはするが、ページごとに書き直す必要があり、属性の取得も、複数値の取得も、すべて自分で面倒を見ることになる。
一周まわって残ったのは、chrome-useの2つのコマンドだ。既知のサイトにはsite、任意のページにはextractを使う。背後にある判断は同じで、データ取得は1回の**宣言的な評価であるべきで、命令的**な往復の列ではない、ということだ。
site:既知のサイトなら、セレクターを自分で書かない
chrome-useが認識しているサイトを開くと、利用可能なadapterがあると自動で示してくれる。
$ chrome-use open https://news.ycombinator.com
💡 site adapters for news.ycombinator.com — prefer these for structured data:
hackernews/thread, hackernews/top
adapterは、特定のサイトに向けてあらかじめ書かれたデータ取得ロジックだ。HNのDOMがどんな形か、これまで何度変わったかを気にする必要はない。
chrome-use site hackernews/top --json
返ってくる1件ごとのデータは完全で、タイトルだけではない。
{ "rank": 1, "title": "ZCode – Harness for GLM-5.2", "url": "https://zcode.z.ai/en",
"author": "chvid", "score": 329, "comments": 258, "id": 48753715,
"hn_url": "https://news.ycombinator.com/item?id=48753715" }
adapterの本当の価値は、「ページ構造は変わる」という問題をあなたの側から切り離してくれることだ。HNが改版されればadapterがそれに合わせて直される。あなたのsite hackernews/topは1文字も変えなくていい。代償は、対応するのが内蔵されたサイトだけに限られることだ。まずchrome-use siteで何があるかを見ればいい。
実際につまずきやすい小さな点が2つある。データは戻り値のトップレベルではなく.data.result.postsにあるので、jqと組み合わせるなら完全なパスを書く必要がある。もう1つ、chrome-useはstderrにバージョン通知を1行出す。それはstdoutのJSONには影響しないが、完全にきれいにしたいなら2>/dev/nullを付ければいい。
extract:任意のページには、セレクターschemaを渡す
既製のadapterがないサイトではextractを使う。ここでまず誤解を正しておきたい。私も最初は間違えたが、これは「欲しいものを自然言語で説明する」ものではない。渡すのはCSSセレクターのschemaだ。
{
"rows": "<css>", // rowsがある:反復コンテナ → 配列を返す。ない → ページ全体に対して1つのオブジェクトを返す
"fields": {
"name": ".title", // 短縮形:セレクター → trim後のテキスト
"href": { "sel": "a", "get": "@href" }, // 属性を取得
"tags": { "sel": ".tag", "get": "text", "all": true } // 一致したものを全部取得 → 配列
}
}
getにはtext(デフォルト)/ @属性 / html / valueを指定できる。HNのトップページから各項目のタイトルとリンクを取るなら、行コンテナは.athingだ。
chrome-use extract --schema '{"rows":".athing","fields":{"title":".titleline a","url":{"sel":".titleline a","get":"@href"}}}'
[ { "title": "ZCode – Harness for GLM-5.2", "url": "https://zcode.z.ai/en" },
{ "title": "Oomwoo, an open-source robot vacuum you build yourself", "url": "https://makerspet.com/blog/..." } ]
rowsを書かなければ、ページ全体に対して1つのオブジェクトを返す。h1やlink[rel=canonical]のようなページ単位のフィールドを取るのに向いている。
もう一段深く考える価値があるのは、その実行方法だ。schema全体は1回のページ評価にコンパイルされる。前のように1フィールドごとに往復するわけではない。10個を超えるフィールドでも1回で取り戻せる。速く、挙動も確定的だ。同じschemaを同じページに当てれば、結果は安定して再現できる。ここが、データ取得において宣言的なやり方が命令的なやり方より扱いやすい理由だ。構造を記述すれば、あとは1回で計算してくれる。セレクターの書き方がわからないなら、まずsnapshot -iで構造を見るか、DevToolsで対象要素をクリックしてselectorを取ればいい。
取れないもの、そして使うべきでないもの
単一コンテナモデルにも届かない場合がある。HNのスコアは.athingの行にはなく、すぐ次の行の.sublineにある。そのため、上の例ではタイトルとリンクだけが取れている。「1件のデータが2行のDOMに分かれている」構造では、rows/fieldsの仕組みだけでは全部を取れない。まさにこれがadapterの存在理由だ。site hackernews/topはすでに2行を結合してくれている。
逆に、そもそもブラウザを開くべきでない場面もある。公開された静的ページの数個のフィールドなら、curl + jqのほうが速い。「どんなページがあるか」を知りたいなら検索エンジンを使うべきだ。extract / siteの本当の主戦場は、ログインが必要で、JSを実行する必要があり、アンチボットに止められるページだ。chrome-useが操作するのは、あなたがその時点でログインしている本物のChromeだからだ。それらのデータはもともと目の前にレンダリングされている。chrome-useは、画面にあるものをJSONとして読み取っているだけだ。CreepJSで実測したbotスコアは0%。偽装しているからではなく、それがもともとあなたのブラウザだからだ。
データ取得で難しいのは、解析そのものではない。解析できる段階までまず到達することだ。前半のログイン、レンダリング、検出の通過はあなた自身のブラウザに任せる。後半では、siteが組み立て済みのレコードを渡し、extractが1つのセレクターで一度にきれいに取らせてくれる。
 微信
微信 支付宝
支付宝
コメント
コメントは即時公開されますが、ポリシー違反時は非表示になる場合があります。