
I tried three clumsy ways to get web data for agents.
The most direct one is to stuff the entire page HTML into the model and let it read for itself. A medium-sized page can take tens of thousands of tokens; before the data is even extracted, half the context is already gone, and the model often reads across lines incorrectly. The second is to write CSS selectors yourself: one find and one get per field. A dozen fields means a dozen round trips, which is slow and verbose. The third is to hand-write a piece of JS eval and run it inside the page. It works, but every page needs its own rewrite, and you have to handle attributes and multiple values yourself.
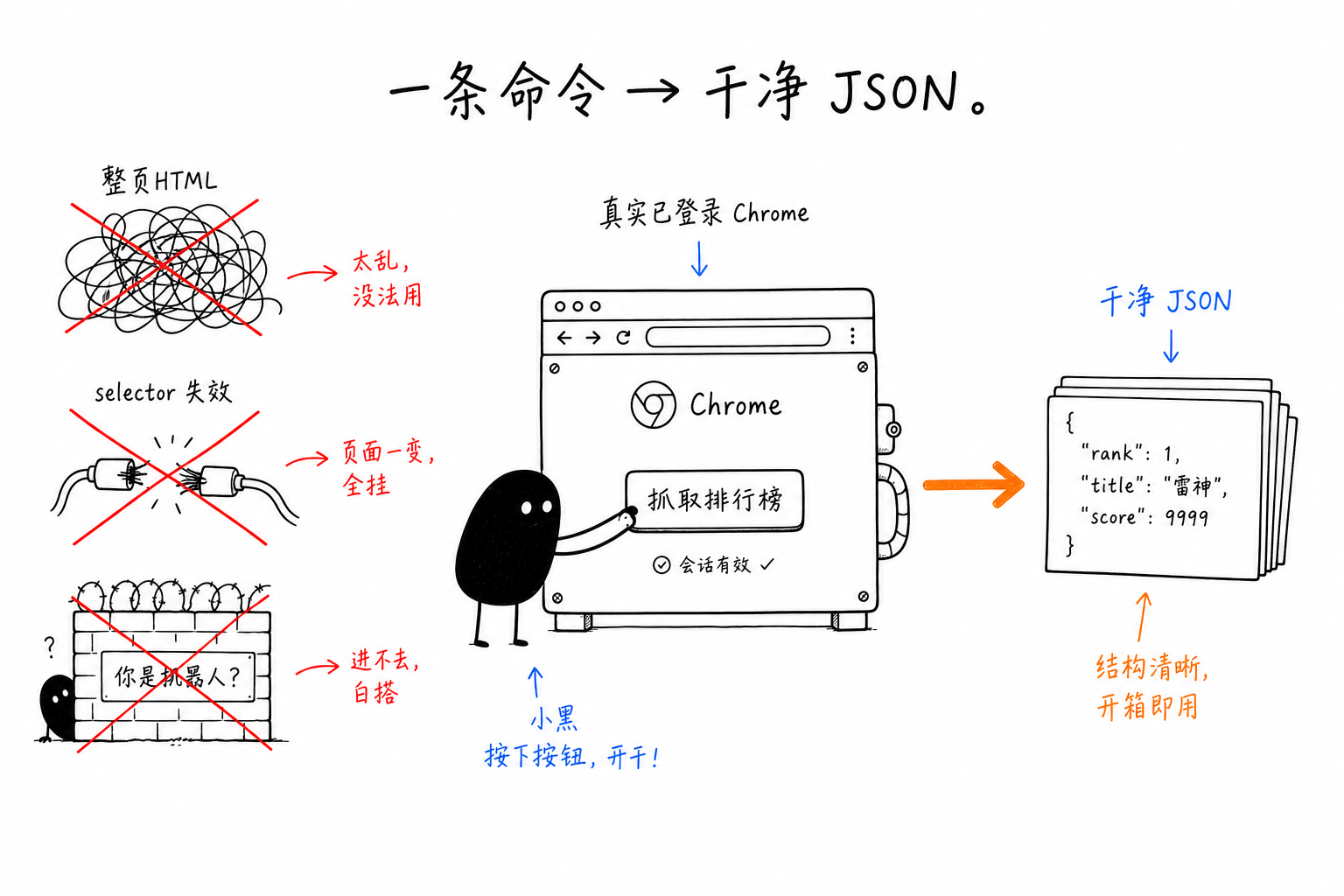
After going in circles, the two commands I kept are from chrome-use: use site for known sites, and extract for arbitrary pages. Behind them is the same judgment: data extraction should be a single declarative evaluation, not a chain of imperative round trips.
site: For known sites, don’t write selectors yourself
Open a site that chrome-use recognizes, and it will tell you that an adapter is available:
$ chrome-use open https://news.ycombinator.com
💡 site adapters for news.ycombinator.com — prefer these for structured data:
hackernews/thread, hackernews/top
An adapter is prewritten extraction logic for a specific site. You do not need to care what HN’s DOM looks like or how many times it has changed:
chrome-use site hackernews/top --json
Each item returned is complete, not just a title:
{ "rank": 1, "title": "ZCode – Harness for GLM-5.2", "url": "https://zcode.z.ai/en",
"author": "chvid", "score": 329, "comments": 258, "id": 48753715,
"hn_url": "https://news.ycombinator.com/item?id=48753715" }
The real value of an adapter is that it moves the problem of “page structure may change” away from you. If HN redesigns, the adapter gets fixed, and your site hackernews/top command does not change by a single character. The cost is that it only covers the built-in sites. Run chrome-use site first to see what is available.
Two small pitfalls you really can run into: the data is in .data.result.posts, not at the top level of the response, so with jq you need to write the full path; chrome-use prints a version notice to stderr, which does not affect the JSON on stdout. If you want it absolutely clean, add 2>/dev/null.
extract: For arbitrary pages, provide a selector schema
For sites without a ready-made adapter, use extract. First, one misunderstanding needs correcting. I got this wrong at the beginning too: it is not “describe what you want in natural language.” Instead, you provide a schema made of CSS selectors:
{
"rows": "<css>", // With rows: repeated container → returns an array; without it → returns one object for the whole page
"fields": {
"name": ".title", // Shorthand: selector → trimmed text
"href": { "sel": "a", "get": "@href" }, // Get an attribute
"tags": { "sel": ".tag", "get": "text", "all": true } // Keep every match → array
}
}
get can be text (default), @attribute, html, or value. To scrape each title and link from the HN front page, the row container is .athing:
chrome-use extract --schema '{"rows":".athing","fields":{"title":".titleline a","url":{"sel":".titleline a","get":"@href"}}}'
[ { "title": "ZCode – Harness for GLM-5.2", "url": "https://zcode.z.ai/en" },
{ "title": "Oomwoo, an open-source robot vacuum you build yourself", "url": "https://makerspet.com/blog/..." } ]
If you omit rows, it returns one object for the whole page. That works well for page-level fields such as h1 or link[rel=canonical].
The part worth thinking about one level deeper is how it executes: the entire schema is compiled into one page evaluation, not the earlier pattern of one round trip per field. A dozen fields still come back in one trip. It is fast, and the behavior is deterministic: apply the same schema to the same page, and the result is stable and reproducible. That is why declarative extraction feels smoother than imperative extraction: you describe the structure, and it computes everything once. Not sure how to write the selector? Use snapshot -i to inspect the structure first, or click the target element in DevTools to get its selector.
What it cannot extract, and when it should not be used
The single-container model also has places it cannot reach. HN’s score is not in the .athing row; it is in the following .subline row. So the example above only gets the title and link. Any structure where “one record is split across two DOM rows” cannot be fully extracted with the rows / fields model. That is exactly why adapters exist: site hackernews/top already stitches those two rows together.
Conversely, some situations should not open a browser at all. For a few fields from a public static page, curl + jq is faster. If you want to know “what pages exist,” use a search engine. The real home turf for extract / site is pages that require login, run JS, or get blocked by anti-bot systems. Because chrome-use operates on the real Chrome you are currently logged into, the data is already rendered in front of you. It is just reading what is on the screen into JSON. In a CreepJS test, the bot score was 0%: not because of disguise, but because it really is your browser.
The hard part of data extraction is never parsing. It is first getting to the point where parsing is possible. Let your own browser handle the first half: login, rendering, and passing detection. For the second half, site gives you assembled records, and extract lets you cleanly extract everything once with a selector schema.
 微信
微信 支付宝
支付宝
Comments
Replies are public immediately and may be moderated for policy violations.