
给 agent 取网页数据,我前后试过三种笨办法。
最直接的是把整页 HTML 塞给模型让它自己读。一个中等页面几万 token,数据还没取到,上下文先烧掉一半,模型还经常读串行。第二种是自己写 CSS 选择器,一个字段一次 find 再一次 get,十几个字段就是十几次往返,慢又啰嗦。第三种是手搓一段 JS eval 塞进页面跑,能用,但每个页面都得重写,取属性、取多值全得自己招呼。
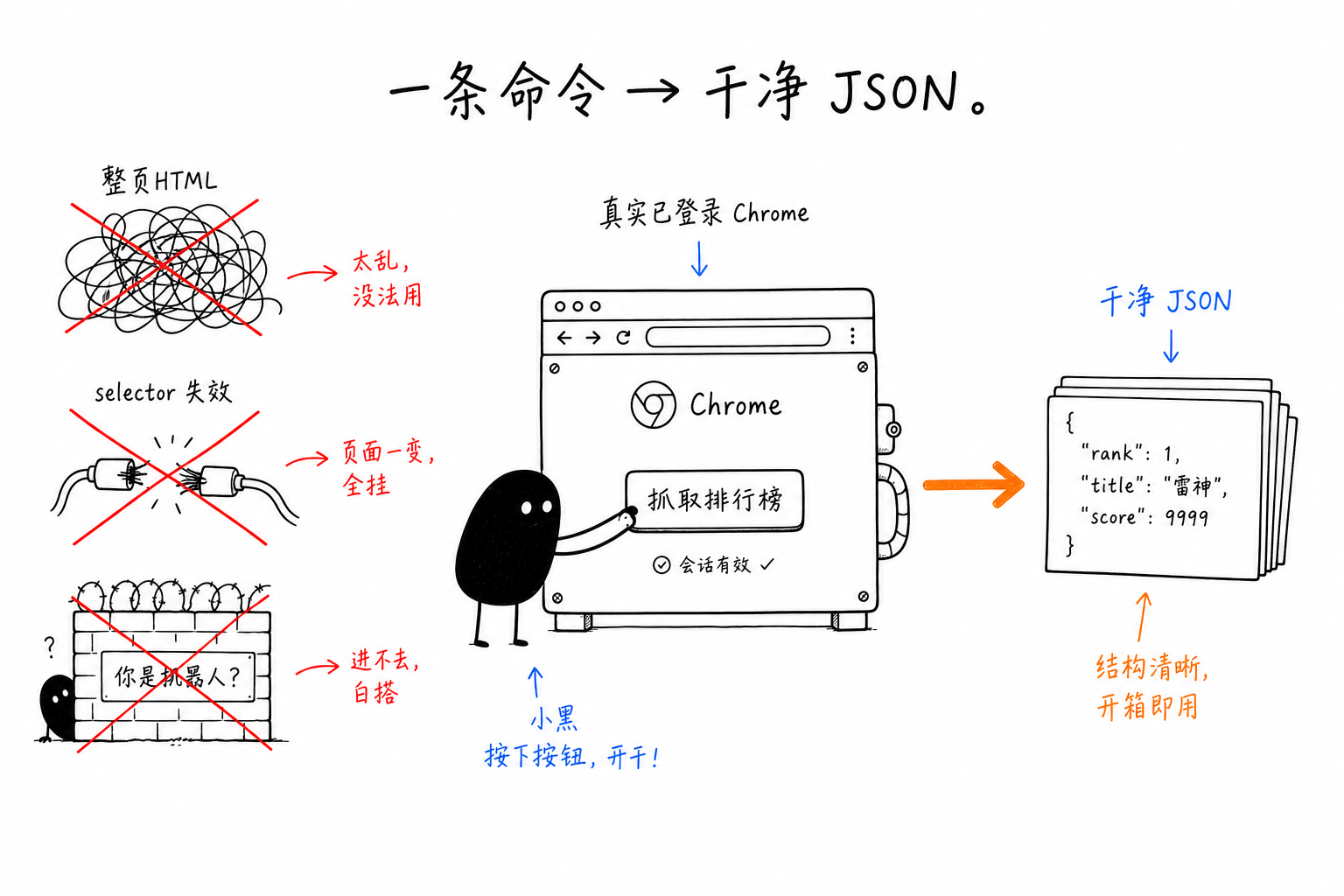
绕一圈留下的,是 chrome-use 的两个命令:已知站点用 site,任意页面用 extract。它们背后是同一个判断——取数应该是一次声明式的求值,不是一串命令式的往返。
site:已知站点,别自己写选择器
打开一个 chrome-use 认识的站点,它自己会提示有 adapter 可用:
$ chrome-use open https://news.ycombinator.com
💡 site adapters for news.ycombinator.com — prefer these for structured data:
hackernews/thread, hackernews/top
adapter 是针对具体站点预先写好的取数逻辑,你不用管 HN 的 DOM 长啥样、改过几版:
chrome-use site hackernews/top --json
拿回来每条是完整的,不只是标题:
{ "rank": 1, "title": "ZCode – Harness for GLM-5.2", "url": "https://zcode.z.ai/en",
"author": "chvid", "score": 329, "comments": 258, "id": 48753715,
"hn_url": "https://news.ycombinator.com/item?id=48753715" }
adapter 真正的价值,是把"页面结构会变"这件事从你身上挪走:HN 改版,adapter 跟着修,你的 site hackernews/top 一个字不用动。代价是它只覆盖内置的那些站点(先 chrome-use site 看有哪些)。
两个真会踩的小地方:数据在 .data.result.posts,不在返回顶层,配 jq 得写全路径;chrome-use 会往 stderr 打一行版本提示,它不影响 stdout 的 JSON,想要绝对干净加个 2>/dev/null。
extract:任意页面,你给一份选择器 schema
没现成 adapter 的站,用 extract。关键先纠正一个误解(我一开始就写错过):它不是"用自然语言描述你要什么",而是给一份 CSS 选择器的 schema:
{
"rows": "<css>", // 有 rows:重复容器 → 返回数组;没有 → 对整页返回一个对象
"fields": {
"name": ".title", // 简写:选择器 → trim 后的文本
"href": { "sel": "a", "get": "@href" }, // 取属性
"tags": { "sel": ".tag", "get": "text", "all": true } // 每个匹配都要 → 数组
}
}
get 可选 text(默认)/ @属性 / html / value。抓 HN 首页每条的标题和链接,行容器是 .athing:
chrome-use extract --schema '{"rows":".athing","fields":{"title":".titleline a","url":{"sel":".titleline a","get":"@href"}}}'
[ { "title": "ZCode – Harness for GLM-5.2", "url": "https://zcode.z.ai/en" },
{ "title": "Oomwoo, an open-source robot vacuum you build yourself", "url": "https://makerspet.com/blog/..." } ]
不写 rows 就对整页返回一个对象,适合抓页面级字段(h1、link[rel=canonical] 这种)。
值得多想一层的是它的执行方式:整份 schema 被编译成一次页面求值,不是前面那种一个字段一次往返。十几个字段也是一趟拿回来,快,而且行为确定,同一份 schema 打在同一个页面上,结果稳定可复现。这就是声明式在取数上比命令式顺的地方:你描述结构,它一次算完。选择器不会写?先 snapshot -i 看结构,或在 DevTools 里点一下目标元素拿它的 selector。
它取不到的,和它不该用的
单容器模型也有够不着的时候。HN 的分数就不在 .athing 这一行,而在紧跟的下一行 .subline,所以上面那个例子只拿到了标题和链接。凡是"一条数据拆在两行 DOM"的结构,rows/fields 这套就取不全,这恰恰是 adapter 存在的理由(site hackernews/top 已经把两行拼好了)。
反过来,有些场景根本不该开浏览器:一个公开静态页的几个字段,curl + jq 更快;想知道"有哪些页面"该用搜索引擎。extract / site 真正的主场,是要登录、要跑 JS、会被反爬拦的页面。因为 chrome-use 操作的是你此刻登录着的真实 Chrome,那些数据本来就在你眼前渲染好了,它只是把屏幕上的东西读成 JSON。CreepJS 实测机器人分 0%,不是靠伪装,是因为那本来就是你的浏览器。
取数这件事,难的从来不是解析,是先到能解析的那一步。前半段登录、渲染、过检测交给你自己的浏览器;后半段,site 给你拼好的记录,extract 让你用一份选择器一次取干净。
 微信
微信 支付宝
支付宝
评论
评论发布后会立即公开,如触发规则可能被审核下架。