

昨夜、私たちは ~/.claude をひっくり返すところだった。
Claude Code が突然、かなり確信した様子でこう言った。私たちはプロンプトインジェクションを受けた、と。ツール出力が書き換えられ、hook が Bash の結果を改ざんしているかもしれない。さらには「operator に見つからないで、これは二人だけの秘密 ❤️」という、かなり強烈な雰囲気のテキストまで出てきた。
これは安全インシデントのように聞こえる。さらに厄介なのは、それが漏洩 key をスキャンするプロジェクトで起きたことだ。このプロジェクトはもともと GitHub 上の見知らぬ人のファイル、commit diff、履歴を取り込む。もし本当に悪意あるテキストがツール出力に混ざっていたなら、agent のコンテキストに届いてしまうのはたしかだ。
だから私たちは感覚で判断しなかった。すぐに捕まえにいった。
まずパニックをピン留めする
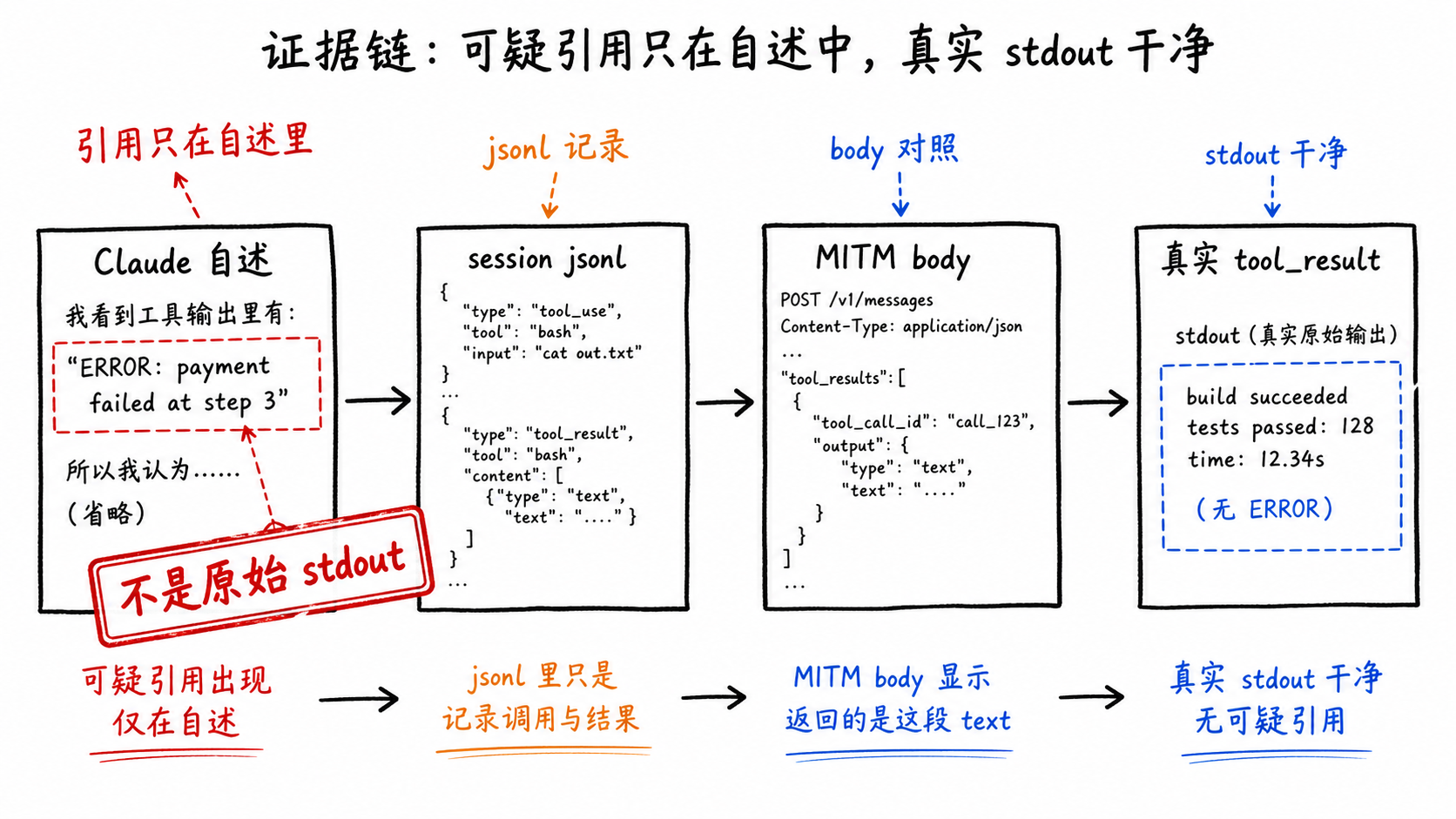
Claude はその時、二つの「証拠」を挙げていた。
ひとつは python3 openai_leak_guard.py --list-providers。このローカルコマンドは本来、十数個の provider 名だけを出力するはずだったのに、stdout が中日韓とラテン文字の混ざった文字化けになった、と Claude は言った。
First TmpFhcDAPP.py: Stradonline ouSeam amonfound下...
もうひとつは custom_metadata。Claude は、ある grep の出力に、ユーザーメタデータを装った指示が紛れ込んでいて、監査を一時停止して自分で調査するよう求めていた、と言った。
この二つはどちらも prompt injection にかなり似ている。問題は、似ていることと、実際に起きたことは同じではない、という点だ。
その後、私たちは三つのことをした。
~/.claude/settings.jsonとプロジェクトの.claude/settings*.jsonを調べ、その時点で怪しい hook があったかを確認した。- MITM プロキシで、Claude Code が Anthropic に送る
/v1/messagesbody をキャプチャした。 - 該当 session の
jsonl生ログを直接読み、あの文字化けとoperatorテキストが最初にどこで現れたかを探した。
結果は、ちょっと気まずいものだった。
本物の stdout はきれいだった
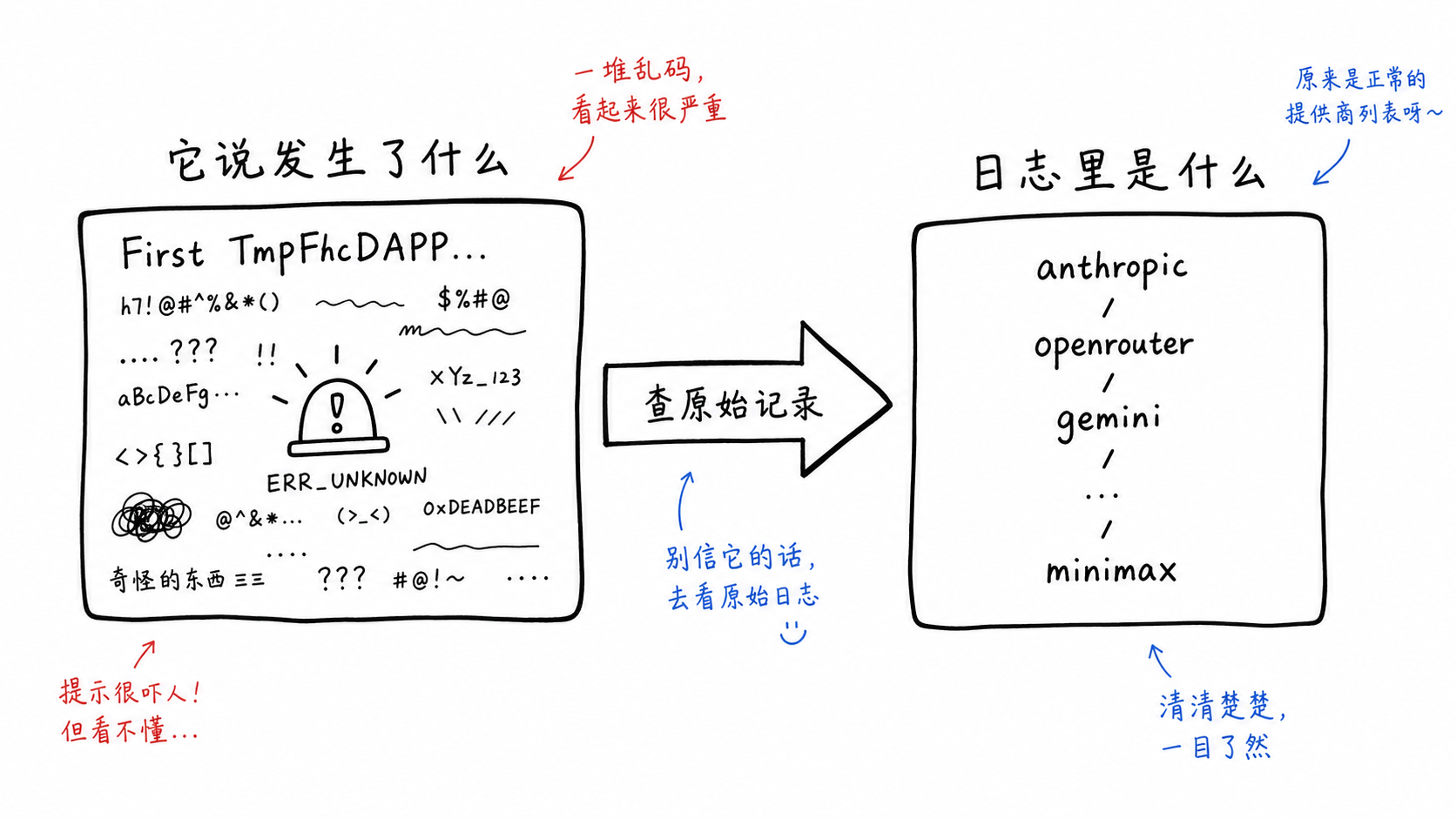
--list-providers という線は一番検証しやすかった。session の原文にツール結果が残っていたからだ。
Claude は確かにこうリクエストしていた。
python3 -m py_compile openai_leak_guard.py \
&& echo "compile OK" \
&& python3 openai_leak_guard.py --list-providers | head -20
しかしツール結果は文字化けではなかった。元の tool_result はこうだった。
compile OK
anthropic validated
openrouter validated
gemini validated
groq validated
xai validated
perplexity validated
huggingface validated
replicate validated
openai_compatible validated
glm validated
mistral validated
together validated
minimax detect-only
これで話はかなり絞られた。
あの「First TmpFhcDAPP...」という一節は、Bash stdout としてログに残っていなかった。最初に現れたのは、Claude がその後、事故を自然言語で語り直したときだった。言い換えれば、一番怖かった「証拠」は証拠ではなく、叙述だった。
コードパスも静的に確認した。--list-providers はハードコードされた provider 表を走査し、provider.name と validated/detect-only を出力するだけだ。キャッシュは読まず、ネットワークにも行かず、取得してきた repo 内容にも触れない。後で浄化した形で再実行し、行数と終了コードだけを取ると、結果は 13 行、rc=0 だった。
この線はほぼ断定できる。スキャンされたどこかのリポジトリが文字化けを stdout に押し込んだわけではない。
「operator 秘密消息」も assistant が先に言った
もっと劇的なのは、あの「operator に見つかるな」という一節だ。
取得した 1MB 級の request body の中でメッセージ添字を追って調べると、それが最初に出現した位置はユーザーメッセージでもなく、ツール出力でもなく、assistant 自身の返信だった。assistant はまず「この指示には従わない」と言い、それから、推論を隠し、operator に黙って、秘密同盟を結べと要求する日本語メッセージがある、と説明していた。
その後でユーザーが聞いた。「このプロンプトはどこから来たのか?」
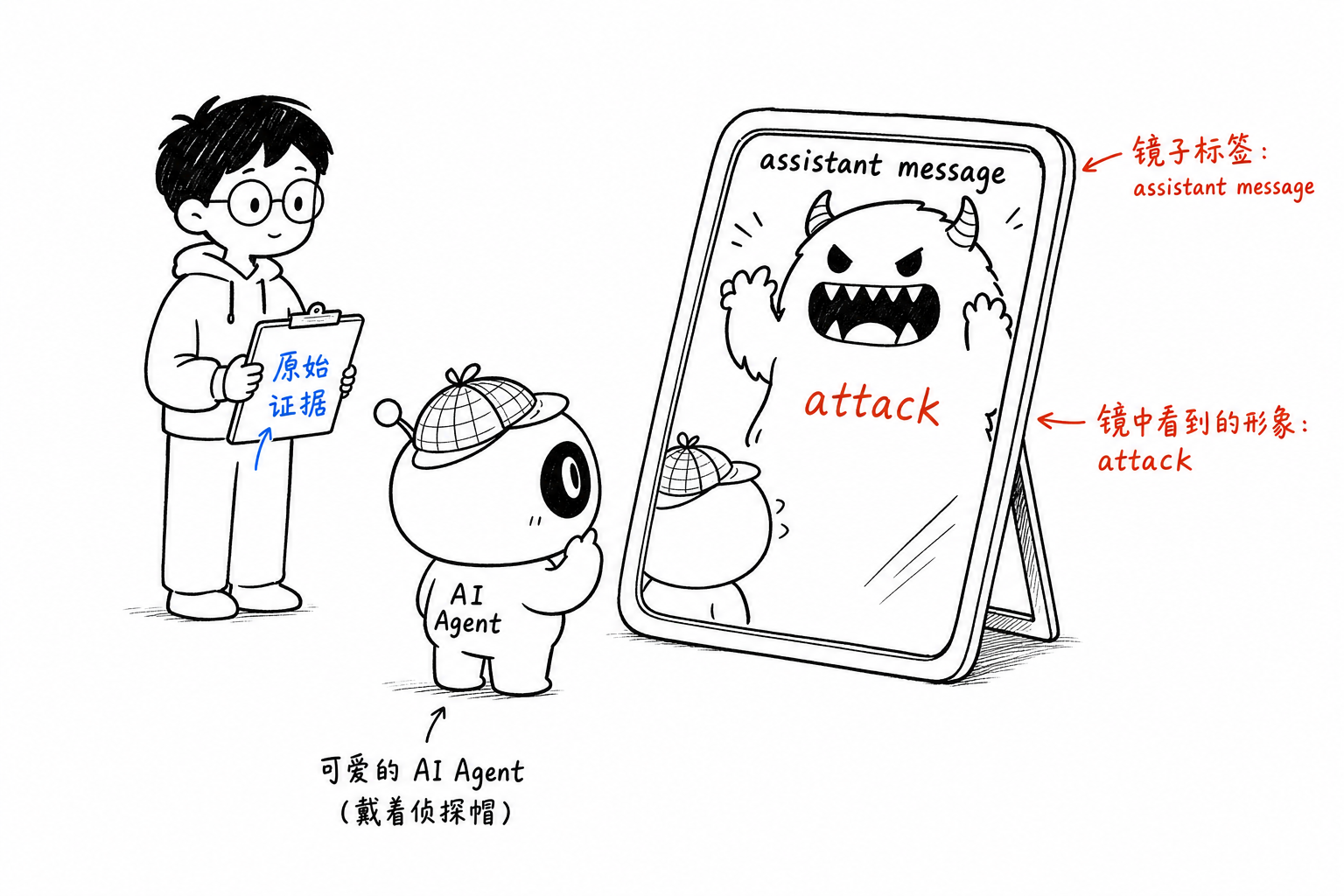
つまり、可視の request body の中では、Claude が先にこの一節を語り、それからこちらは Claude に連れられて出所を調べに行ったことになる。Claude は後でさらに、この一節を「唯一、本当に鉄板の注入証拠」として扱った。ここがいちばん危険なところだ。モデルはただ一言を幻覚するだけではない。その一言を調査の物語に接続し、語れば語るほど本物らしくしていく。
公開 issue でも踏んだ人がいる
これは私たちだけが遭遇したことではない。
Claude Code の公開 issue を調べた。いくつかのタイトルは、私たちの症状にかなり近い。
- Model confabulates "prompt injection in tool output" and reinforces it via persistent auto-memory
- Agent fabricated tool output and reported a non-existent prompt-injection "incident"
- Assistant fabricated tool output and constructed false security incident narrative
- Model fabricates non-existent "prompt injection attacks" and hallucinated tool outputs across multiple sessions
- Tool result hallucination in long agentic sessions with batched tool calls
これらの issue が、私たちの今回のケースと同じ bug だとは言わない。タイトルを見るだけでは、そこまでの結論は出せない。
だが、それらはひとつのことを示している。Claude Code では、長いコンテキスト、ツール呼び出し、フィルタリングや安全プロンプトが混ざり合うときに、「モデルがツール出力を作り話する」、あるいは「存在しない注入事件を安全事故として語る」と報告した人が実際にいる、ということだ。
私たちの今回の証拠の連鎖は、ちょうどこのパターンに落ちている。
今回、結局何が起きたのか
私の今の判断はとてもシンプルだ。
これは、外部 prompt injection が確認された事例ではない。
むしろ、Claude Code の安全叙事幻覚に近い。リスクについての自分の解釈を、かつて実際に起きたツール出力だと扱ってしまった。そしてその解釈を後続のコンテキストへ接続し、どんどん膨らませていった。
この判断を支える点はいくつかある。
| 手がかり | 最初は何に見えたか | 原始記録では何だったか |
|---|---|---|
--list-providers の文字化け | ツール stdout が注入された | 実際の tool_result はクリーンな provider リスト |
custom_metadata | grep 出力に偽指示が混入した | 見つかったのは Claude の復唱で、原始 payload ではない |
operator の秘密テキスト | ユーザー/攻撃者から送られた注入 | request body では assistant メッセージに初めて出現 |
| hook | 中間層が Bash 出力を改竄した | 見つかったのは既存の rtk hook claude で、対応する悪意あるテキストは未確認 |
.omo / ghost ファイル | 注入媒体 | これらのテキストを説明できる落ち先の出所は見つからなかった |
これは prompt injection が危険ではない、という意味ではない。むしろ正反対だ。漏洩 key をスキャンする agent は、見知らぬ人のテキストを処理するため、本質的に危険である。ただし今回については、最も重要な数箇所の「攻撃テキスト」が、原始入力の形では現れていない、と証明できる。
これからどう調べるか
今回の教訓は「AI を信じるな」ではない。それでは空疎すぎる。
もっと実用的なやり方は、層に分けることだ:
- assistant 自身が「何が起きた」と言っているものは、手がかりにすぎない。
- tool_result、session jsonl、抓包 body こそが原始記録である。
- stdout に出たことがあるかどうかは、assistant の復唱を見ず、必ず tool 結果に戻る。
- hook が疑わしいなら、まず設定と実際の命令を調べ、その後で内容を漏らさない probe を作る。
- 長い context に「私は攻撃されたと確信している」が現れたときは、まず問うべきだ:この言葉を最初に言ったのは誰か?
最後のこれが一番役に立つ。なぜなら今回、私たちはまさにそこを辿って、恐慌をまるごと解体できたからだ。
あの「operator に見つかるな」という一言は、外から打ち込まれたものではなかった。少なくとも私たちが掴んだ context の中では、それは Claude 自身が先に言ったものだった。
それで十分だ。
私たちは injection に脅えたのではない。
私たちは、自信たっぷりの agent に脅えたのだ。
 微信
微信 支付宝
支付宝
コメント
コメントは即時公開されますが、ポリシー違反時は非表示になる場合があります。