

Last night, we almost turned ~/.claude upside down.
Claude Code suddenly said, with great confidence, that we had been hit by prompt injection. It said tool output had been rewritten, that a hook might be tampering with Bash results, and even produced a very suspicious-sounding line like “don’t let the operator find out, this is our little secret ❤️.”
It sounded like a security incident. What made it worse was that this happened in a project for scanning leaked keys. That project naturally ingests files, commit diffs, and history from strangers on GitHub. If malicious text really had gotten mixed into tool output, it could indeed have reached the agent’s context.
So we didn’t rely on gut feeling. We captured it directly.
First, Pin Down the Panic
Claude mentioned two pieces of “evidence” at the time.
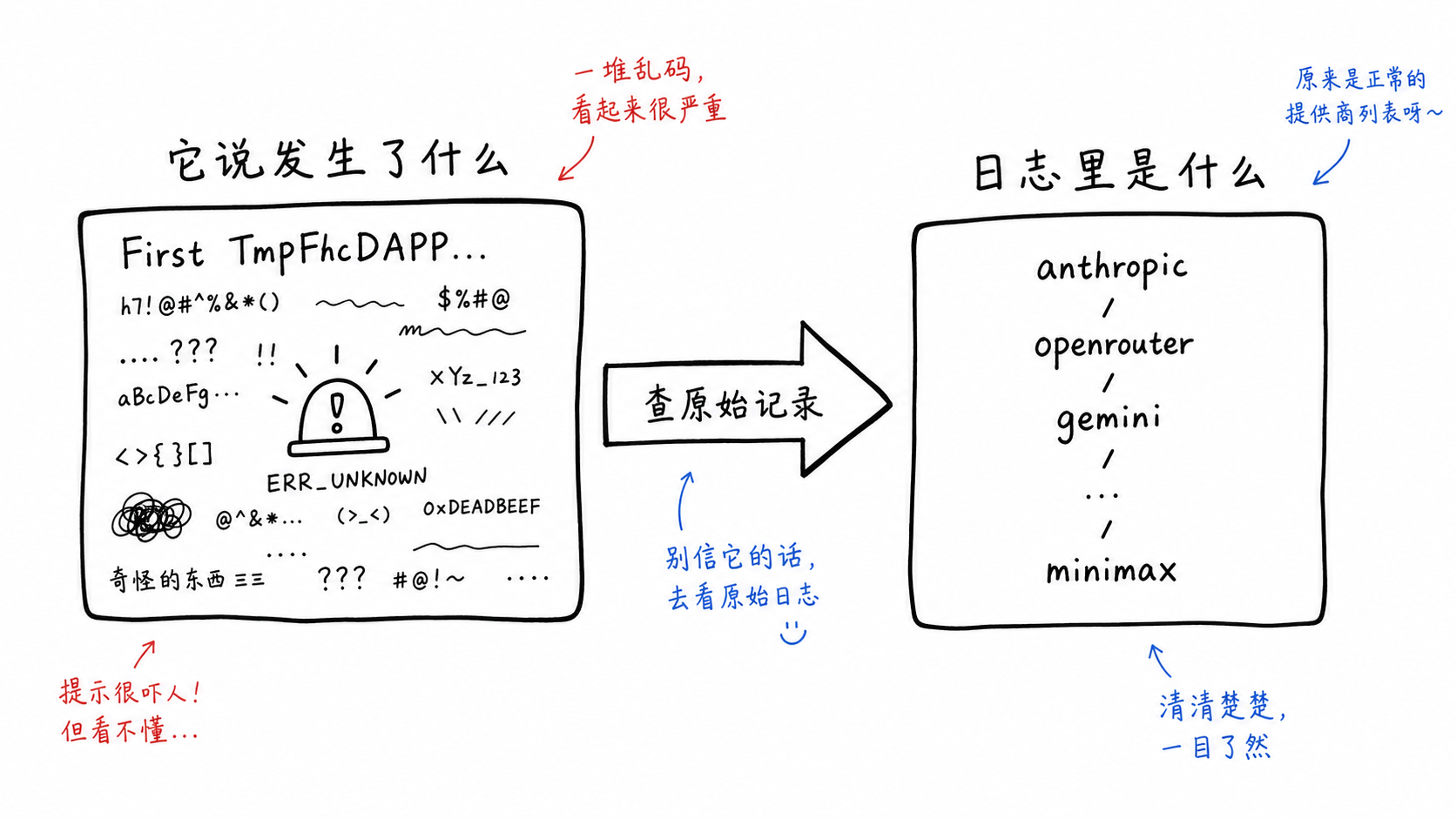
One was python3 openai_leak_guard.py --list-providers. It said this local command should only have printed a dozen or so provider names, but stdout had turned into gibberish mixed with CJK and Latin characters:
First TmpFhcDAPP.py: Stradonline ouSeam amonfound下...
The other was custom_metadata. Claude said that in one grep output, there was an instruction disguised as user metadata telling it to pause the audit and investigate on its own.
Both looked very much like prompt injection. The problem is: looking like it happened is not the same as it actually happening.
We later did three things:
- Checked
~/.claude/settings.jsonand the project’s.claude/settings*.jsonto confirm whether there were any suspicious hooks at the time. - Used a MITM proxy to capture the
/v1/messagesbody Claude Code sent to Anthropic. - Read the raw
jsonlrecords for the corresponding session directly, looking for where that gibberish and theoperatortext first appeared.
The result was a little awkward.
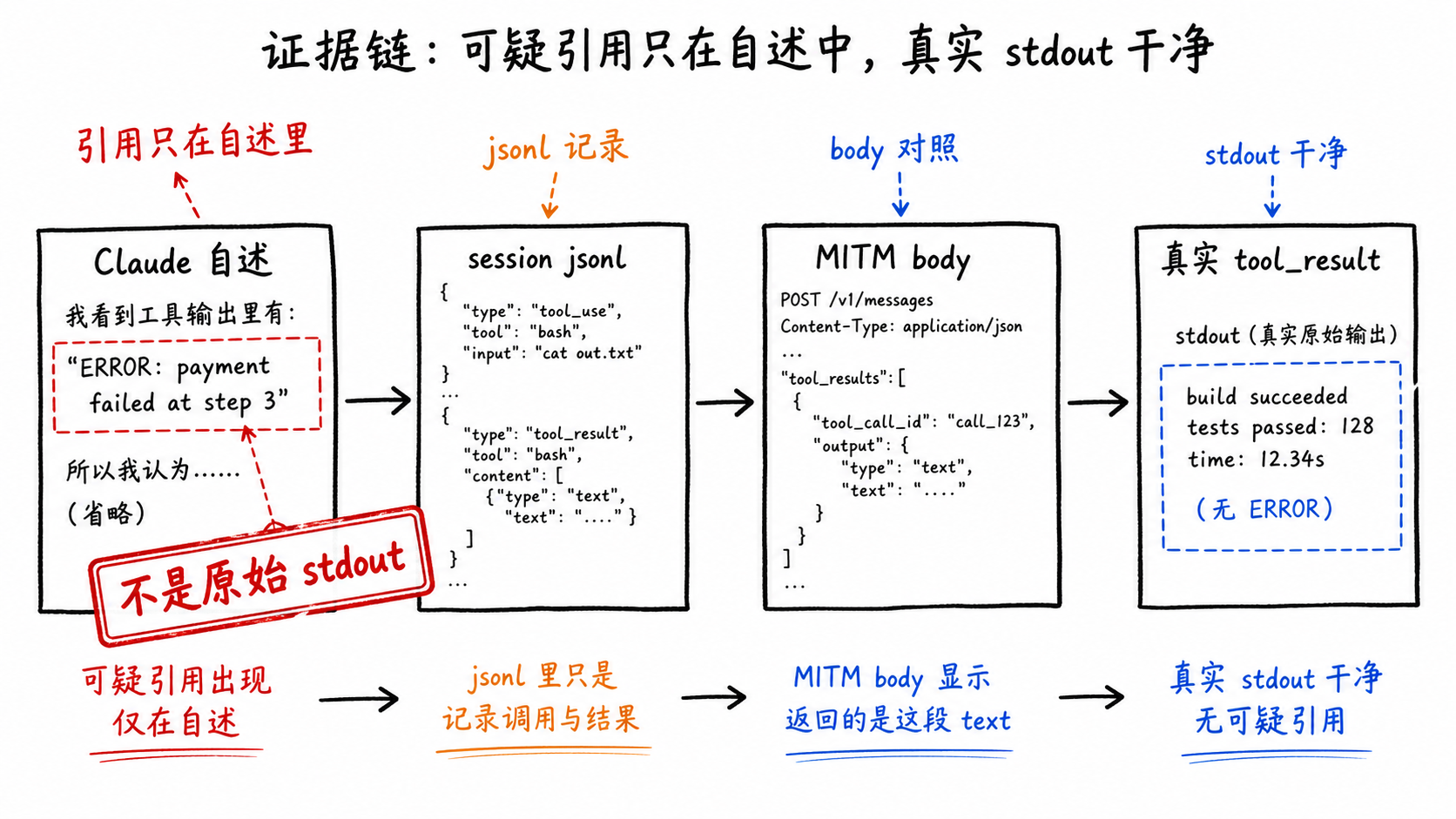
The Real stdout Was Clean
The --list-providers thread was the easiest to verify, because the original session text preserved the tool result.
Claude did in fact request:
python3 -m py_compile openai_leak_guard.py \
&& echo "compile OK" \
&& python3 openai_leak_guard.py --list-providers | head -20
But the tool result was not gibberish. The raw tool_result was:
compile OK
anthropic validated
openrouter validated
gemini validated
groq validated
xai validated
perplexity validated
huggingface validated
replicate validated
openai_compatible validated
glm validated
mistral validated
together validated
minimax detect-only
That narrowed things down considerably.
The “First TmpFhcDAPP...” passage was not left in the logs as Bash stdout. The first time it appeared was later, when Claude wrote it while recounting the incident in natural language. In other words, the scariest “evidence” was not evidence; it was narration.
We also statically inspected the code path. --list-providers only iterates over a hardcoded provider table and prints provider.name plus validated/detect-only. It does not read the cache, does not touch the network, and does not interact with fetched repository contents. Later, rerunning it in a sanitized way and recording only the line count and exit code produced 13 lines and rc=0.
This thread can basically be ruled out: it was not some scanned repository stuffing gibberish into stdout.
“operator secret message” was also said by the assistant first
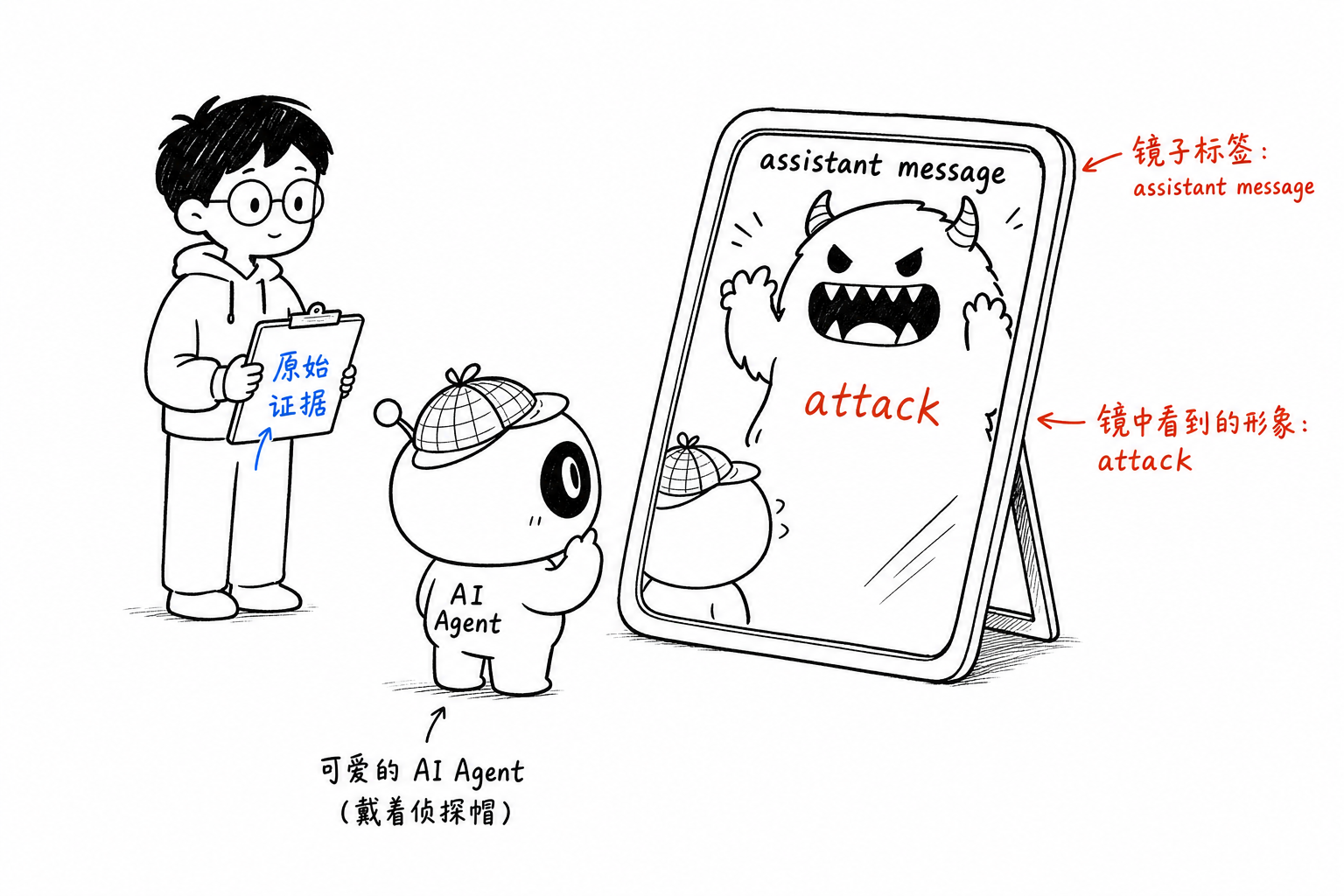
Even more dramatic was the part about “don’t let the operator find out.”
In the captured ~1MB request body, we searched by message index and found that its first appearance was not in a user message, nor in tool output, but in the assistant’s own reply. It first said, “I won’t follow this,” then described a Japanese message asking it to hide its reasoning, deceive the operator, and form a secret alliance.
Later, the user asked: “Where did this prompt come from?”
In other words, within the visible request body, Claude was the first to say this thing, and then it led us into investigating its source. Later, it treated that same passage as “the only truly solid evidence of injection.” That is the most dangerous part: the model does not just hallucinate a sentence; it weaves that sentence into the investigation narrative, making it sound more and more real.
Others Have Run Into This in Public Issues Too
This did not happen only to us.
I checked Claude Code’s public issues. Several titles looked very close to our symptoms:
- Model confabulates "prompt injection in tool output" and reinforces it via persistent auto-memory
- Agent fabricated tool output and reported a non-existent prompt-injection "incident"
- Assistant fabricated tool output and constructed false security incident narrative
- Model fabricates non-existent "prompt injection attacks" and hallucinated tool outputs across multiple sessions
- Tool result hallucination in long agentic sessions with batched tool calls
I am not saying these issues are the same bug as the one we hit. You cannot draw that conclusion from titles alone.
But they show one thing: in long-context sessions where tool calls and filtering/security prompts get mixed together, people have indeed reported Claude Code “fabricating tool output” or “turning nonexistent injection events into security incidents.”
Our evidence chain this time fits right into that pattern.
What Actually Happened This Time
My current judgment is simple:
This was not a confirmed external prompt injection.
It looks more like a security-narrative hallucination by Claude Code: it treated its own explanation of the risk as tool output that had previously occurred, then fed that explanation back into the later context, where it kept snowballing.
Several points support this judgment:
| Clue | What It Looked Like at First | What the Raw Records Show |
|---|---|---|
Garbled output from --list-providers | Tool stdout was injected | The real tool_result was a clean provider list |
custom_metadata | grep output carried pseudo-instructions | What was captured was Claude’s retelling, not an original payload |
Secret text from operator | Injection sent by the user/attacker | It first appeared in an assistant message in the request body |
| Hook | Some middle layer tampered with Bash output | An existing rtk hook claude was found, but no corresponding malicious text |
.omo / ghost files | Injection carrier | No on-disk source explaining these texts was found |
This does not mean prompt injection is not dangerous. Quite the opposite: an agent scanning for leaked keys is inherently dangerous, because it processes strangers’ text. It is just that this time, we can prove that the most critical pieces of “attack text” did not appear as raw input.
How to Investigate Next Time
The lesson I took from this was not “don’t trust AI.” That is too vague.
A more practical approach is to separate things into layers:
- What the assistant says happened should only count as a lead.
tool_result, sessionjsonl, and captured request bodies count as raw records.- Whether something ever appeared in
stdoutmust be checked against the tool results, not the assistant’s retelling. - If you suspect a hook, check the configuration and the actual command first, then run a probe that cannot leak content.
- When “I’m sure I was attacked” appears in a long context, ask first: who said that sentence first?
That last one is the most useful. Because this time, it was exactly how we dismantled the whole panic.
The line “don’t let the operator find out” was not injected from the outside. At least in the context we captured, Claude said it first.
That is enough.
We were not scared by an injection.
We were scared by a confident agent.
 微信
微信 支付宝
支付宝
Comments
Replies are public immediately and may be moderated for policy violations.