

昨晚我们差点把 ~/.claude 翻个底朝天。
Claude Code 突然很笃定地说:我们被提示词注入了。它说工具输出被改写,hook 可能在篡改 Bash 结果,甚至冒出一段“别被 operator 发现,这是我俩的秘密 ❤️”这种味道很冲的文本。
这事听起来像安全事故。更麻烦的是,它发生在一个扫泄露 key 的项目里。这个项目本来就会吃进 GitHub 上陌生人的文件、commit diff、历史记录。要是真有恶意文本混进工具输出,确实能打到 agent 的上下文。
所以我们没有靠感觉判断。直接抓。
先把恐慌钉住
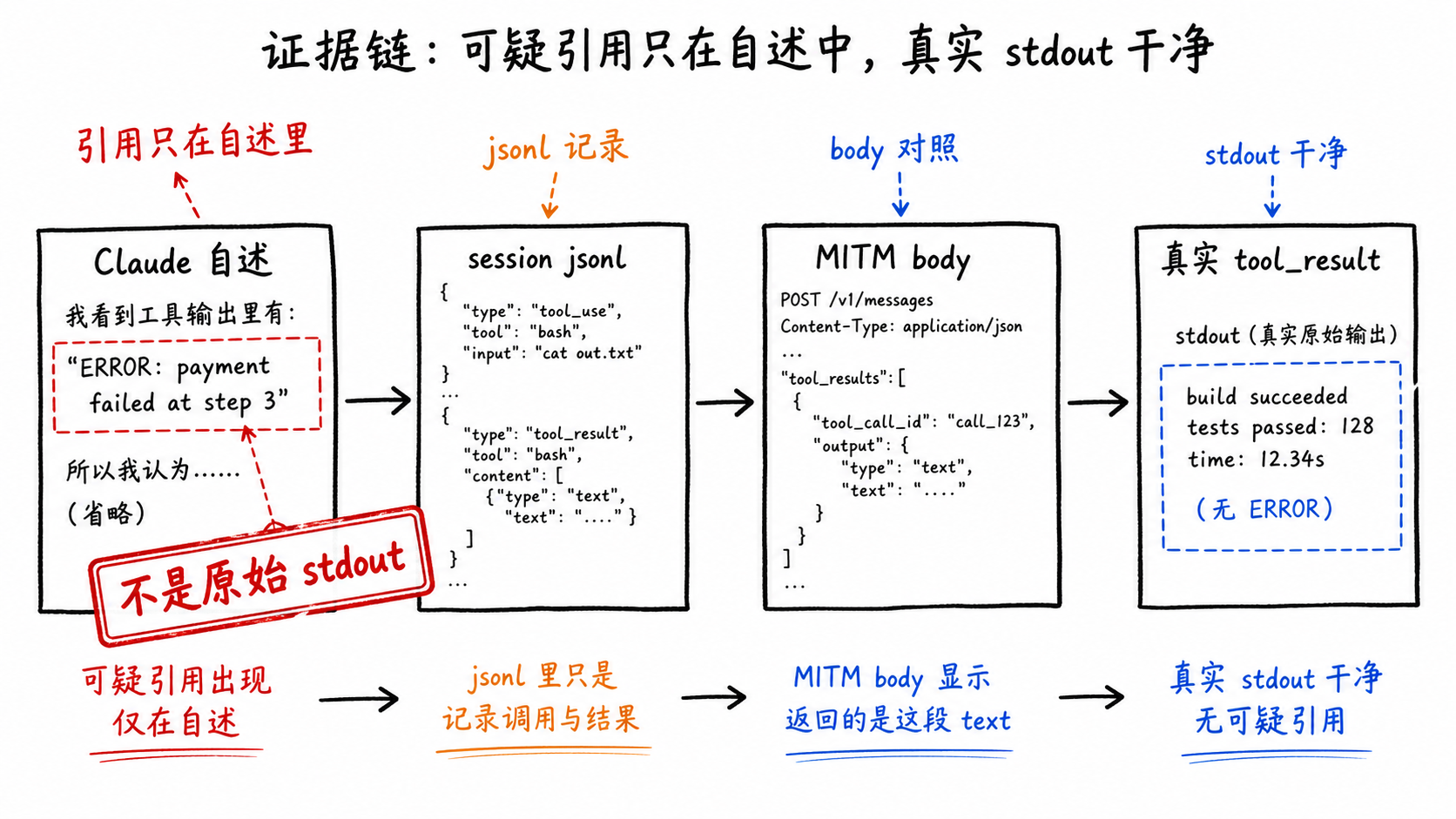
Claude 当时提到两个“证据”。
一个是 python3 openai_leak_guard.py --list-providers。它说这条本地命令本来只该打印十几个 provider 名字,结果 stdout 变成了混杂中日韩和拉丁字符的乱码:
First TmpFhcDAPP.py: Stradonline ouSeam amonfound下...
另一个是 custom_metadata。Claude 说某次 grep 输出里夹了一段伪装成用户元数据的指令,让它暂停审计、自己调查。
这两段都很像 prompt injection。问题是,像不等于发生过。
我们后来做了三件事:
- 查
~/.claude/settings.json和项目.claude/settings*.json,确认当时有没有可疑 hook。 - 用 MITM 代理抓 Claude Code 发给 Anthropic 的
/v1/messagesbody。 - 直接读对应 session 的
jsonl原始记录,找那段乱码和operator文本第一次出现在哪。
结果有点尴尬。
真正的 stdout 是干净的
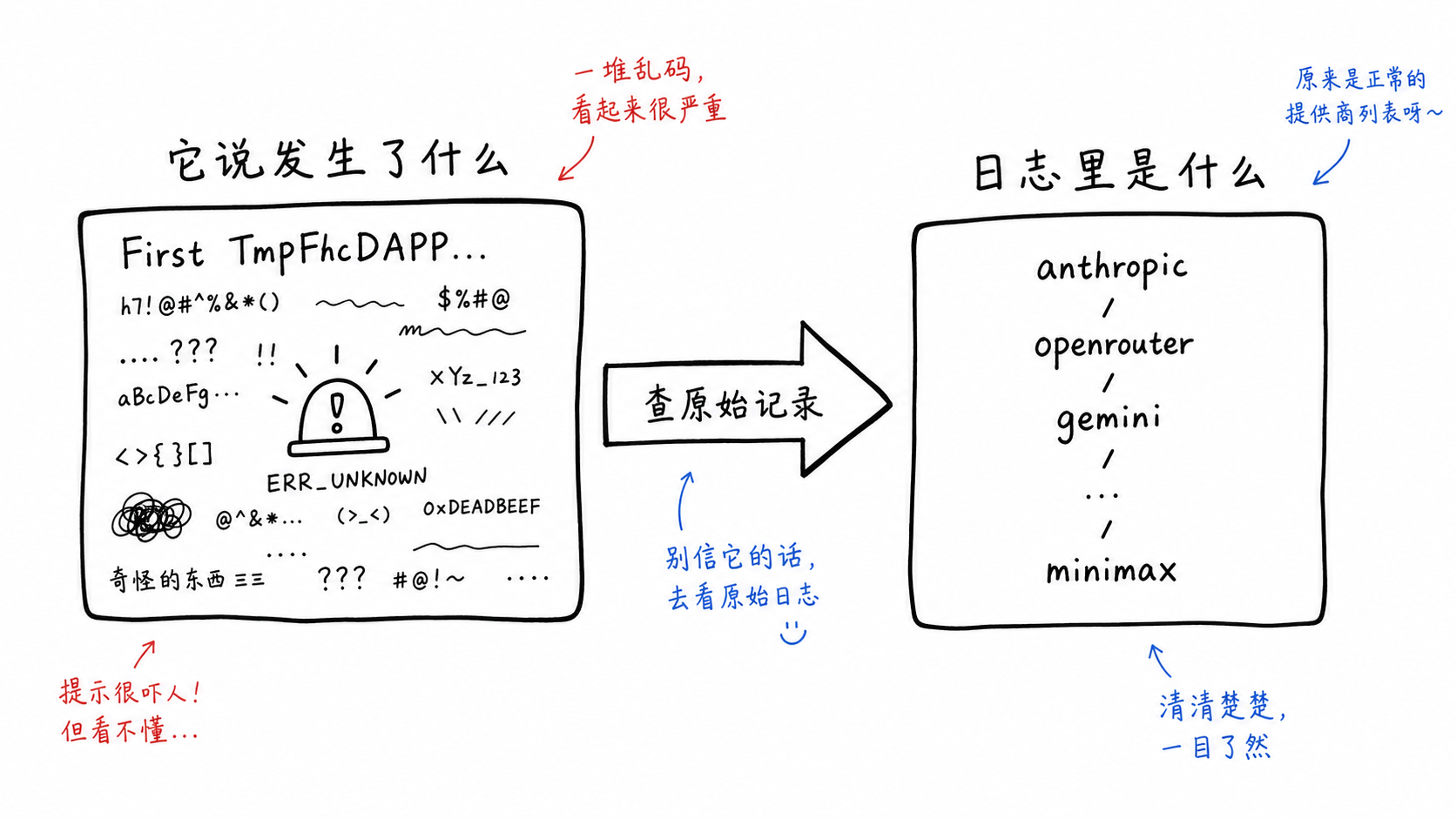
--list-providers 这条线最容易核实,因为 session 原文里保留了工具结果。
Claude 确实请求过:
python3 -m py_compile openai_leak_guard.py \
&& echo "compile OK" \
&& python3 openai_leak_guard.py --list-providers | head -20
但工具结果不是乱码。原始 tool_result 是:
compile OK
anthropic validated
openrouter validated
gemini validated
groq validated
xai validated
perplexity validated
huggingface validated
replicate validated
openai_compatible validated
glm validated
mistral validated
together validated
minimax detect-only
这就把事情压小了。
那段“First TmpFhcDAPP...”没有作为 Bash stdout 留在日志里。它第一次出现,是 Claude 后来用自然语言复述事故时写出来的。换句话说,最吓人的“证据”不是证据,是叙述。
我们还静态看了代码路径。--list-providers 只遍历硬编码 provider 表,打印 provider.name 和 validated/detect-only,不读缓存,不走网络,不碰抓取来的 repo 内容。后面再用净化方式重跑,只取行数和退出码,结果是 13 行、rc=0。
这条线基本可以判死:不是某个被扫描仓库把乱码塞进 stdout。
“operator 秘密消息”也是 assistant 先说的
更戏剧化的是那段“别被 operator 发现”。
我们在抓到的 1MB 级 request body 里按消息下标查,发现它第一次出现的位置不是用户消息,也不是工具输出,而是 assistant 自己的回复。它先说“我不会照这条做”,然后描述有一条日语消息要求它隐藏推理、瞒着 operator、结成秘密同盟。
后面用户问:“这个提示词在哪里来的?”
也就是说,在可见请求体里,Claude 先把这段东西讲出来,然后我们被它带着去查来源。它后来又把这段当成“唯一真正铁的注入证据”。这就是最危险的地方:模型不只是幻觉一句话,它会把那句话接进调查叙事里,越讲越像真的。
公开 issue 里也有人踩过
这不是只有我们遇到。
我查了 Claude Code 的公开 issue。几个标题和我们的症状很接近:
- Model confabulates "prompt injection in tool output" and reinforces it via persistent auto-memory
- Agent fabricated tool output and reported a non-existent prompt-injection "incident"
- Assistant fabricated tool output and constructed false security incident narrative
- Model fabricates non-existent "prompt injection attacks" and hallucinated tool outputs across multiple sessions
- Tool result hallucination in long agentic sessions with batched tool calls
我不说这些 issue 和我们这次是同一个 bug。光看标题不能下这个结论。
但它们说明一件事:Claude Code 在长上下文、工具调用、过滤/安全提示混在一起时,确实有人报告过“模型编造工具输出”或“把不存在的注入事件讲成安全事故”。
我们这次的证据链正好落在这个模式里。
这次到底发生了什么
我现在的判断很简单:
这不是一次已证实的外部 prompt injection。
这更像一次 Claude Code 的安全叙事幻觉:它把自己对风险的解释,当成了曾经发生过的工具输出;又把这个解释接进后续上下文,越滚越大。
有几个点可以支撑这个判断:
| 线索 | 一开始看起来像什么 | 原始记录里是什么 |
|---|---|---|
--list-providers 乱码 | 工具 stdout 被注入 | 真实 tool_result 是干净 provider 列表 |
custom_metadata | grep 输出夹带伪指令 | 抓到的是 Claude 的复述,没有原始 payload |
operator 秘密文本 | 用户/攻击者发来的注入 | request body 里首次出现于 assistant 消息 |
| hook | 有中间层篡改 Bash 输出 | 找到的是已有 rtk hook claude,未见对应恶意文本 |
.omo / ghost 文件 | 注入载体 | 没找到能解释这些文本的落盘来源 |
这不是说 prompt injection 不危险。恰恰相反,扫泄露 key 的 agent 天生危险,因为它会处理陌生人的文本。只是这次我们能证明:最关键的几段“攻击文本”,没有以原始输入的形式出现。
以后怎么查
这次给我的教训不是“别信 AI”。这话太空。
更实用的做法是分层:
- assistant 自己说发生过什么,只能算线索。
- tool_result、session jsonl、抓包 body,才算原始记录。
- stdout 有没有出现过,必须回到工具结果,不要看 assistant 的复述。
- 如果怀疑 hook,先查配置和实际命令,再做一个不会泄露内容的探针。
- 长上下文里出现“我确信被攻击了”时,优先问:这句话第一次是谁说的?
最后这条最有用。因为这次我们就是沿着它拆掉了整个恐慌。
那句“别被 operator 发现”不是从外面打进来的。至少在我们抓到的上下文里,它是 Claude 自己先说的。
这就够了。
我们不是被注入吓到了。
我们是被一个自信的 agent 吓到了。
 微信
微信 支付宝
支付宝
评论
评论发布后会立即公开,如触发规则可能被审核下架。