
一目で偽物だとばれる、敗因はリズム
導入先から1枚のスクリーンショットが送られてきた。ユーザーがセンシティブな話題を一言たずねると、こちらのAI彼女は6つの吹き出しで返した。「はは」「なんで急にそんなこと聞くの〜?政治のことはあまり分からないな」「そういうのもあまり追ってないし。」「たとえば今日の予定は?」「別の話しよ」「😅」。合計で約50字、間隔ゼロ、同じ瞬間に画面いっぱいへ流れ込んだ。人間が50字を打つには少し時間がかかる。ここでは1フレームで全部そろってしまい、チャットというよりバッチ処理の出力に見えた。
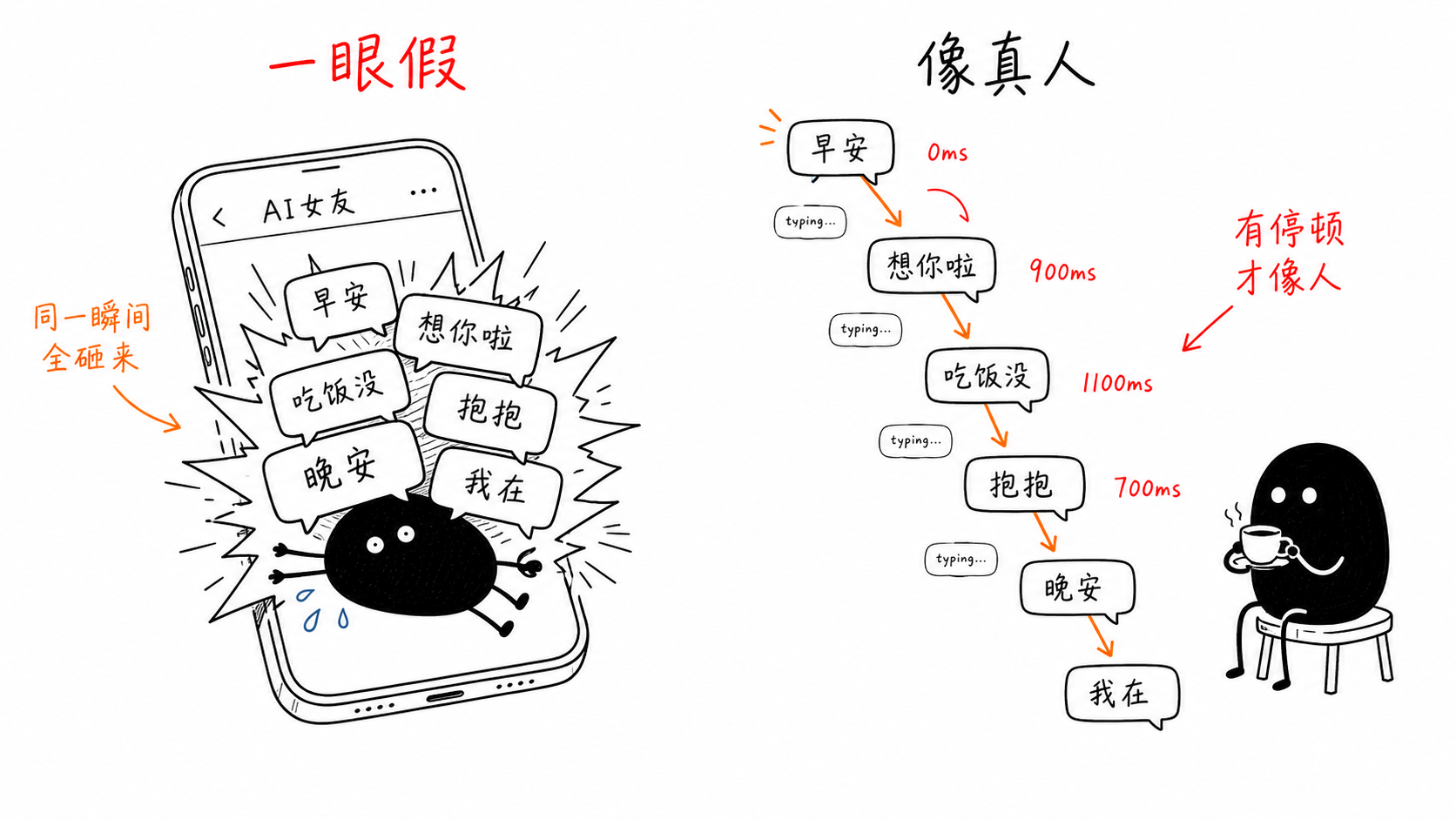
分解して見ると、この50字には3層の問題が重なっていた。いちばん目立ったのはリズムだ。下流が受け取ったdelayフィールドはすべて0で、6通のメッセージが同時に画面へ出た。切り分け方もよくなかった。吹き出しを分ける本来の意図は、人間のように一文を数通に分けて送ることだった。しかし切り分けロジックは句読点ごとに切っており、普通の返答が6つに刻まれ、あの😅まで1通を占めていた。残りは内容の問題だ。同じ「政治は分からない」を言い方を変えて3回述べ、さらに「今日の予定は?」という無理な質問で話題をそらそうとしていた。3つの謝罪が詰め込まれ、情報量は1文ぶんしかない。内容の責任はprompt側にある。その場でユーザーを現実に引き戻してしまったのは、前の2層だった。
人間は答えたくない話題を聞かれると、まず数秒止まる。相手に見えるのは「入力中」で、そのあと1通ずつ届く。私たちはそれに合わせて修正した。コールバック内の各メッセージにdelayフィールドを持たせた。最初の1通は常に0にする。ユーザーがメッセージを送ってから最初の返答までには、モデル生成の時間がもともとかかる。この空白がすでに「彼女が考えている」演出をしてくれているので、さらにdelayを重ねると鈍く見えるだけだ。以後の各通は内容の長さに応じてタイピングを模擬する。基本は500ms、1文字ごとに55msを足し、結果を600〜2600msの間に収める。さらに±15%のランダムな揺れを加え、各間隔が機械的に同じ長さにならないようにする。それもまたばれるからだ。画像は別扱いで1800msにした。アルバムをめくって写真を選ぶほうが、文字を打つより一拍遅い。上限も管理する必要がある。1通は最大4000ms、返答全体の累計は16000ms以内に抑える。下流プロトコルには20000msの切り捨てラインがあるため、余裕を残さなければならない。そうしないとdelayが詰められて変形し、せっかく整えたリズムがまた崩れる。
このプロダクトを作る前、難しいのはAIを速くすることだと思っていた。実際に作り始めて、逆だと分かった。難しいのは、人間らしく「遅く」することだった。私たちは意図的な初回応答遅延まで書いた。知らない人同士の段階では、最初の返答をランダムに4.5〜10秒待ってから送る。知り合ったばかりの人は、画面に張り付いてあなたを待っているわけではない。返信の速さはまちまちだ。毎回即レスすると、「いつでもオンラインで待機中」と顔に書いてあるようなもので、かえって偽物っぽくなる。
このdelay群を本番投入したあと、同じ一連の返答にも少なくとも順番と間が生まれた。あの6つの吹き出しのスクリーンショットは、私たちが払った最初の授業料だった。その後の3層の問題にはそれぞれ修正方法があるが、道理は同じだ。ばれないAIチャット相手を作る勝負どころは、モデルではなくエンジニアリングの細部にある。
プロンプトは層になっていて、教訓もまた層になっている
私たちの system prompt は組み上げると1万3千 token 以上になるが、最初から一枚岩の文章だったわけではない。何層にも重ねて作っている。いちばん内側には、コードにハードコードされたレッドラインがある。身元の明示、出力フィルタ、反インジェクション。ここはどのテナントも変更できない。その外側に、テナント単位の「共通行動レイヤー」がある。13,449文字の大きなテキストで、話し方、拒否の仕方、メッセージの分割方法を管理する。いちばん外側になってようやく、各キャラクターの説明が来る。ここは四、五百文字しかない。人格設定の横には、構造化された「ハードファクト」もぶら下げている。年齢、都市、家族のような数値型・事実型の情報は、散文の中に埋めず、別に列挙する。さらに後ろに、現在の状態に応じて差し込む動的ブロックが続く。時刻、関係段階、場面、会話記憶だ。
91%が制約で、新しい指示は底に沈んだ
一時期、特定の人格設定だけ少し自由に振る舞わせたくて、prompt に指示を追加したことがある。モデルの挙動はびくともしなかった。あとで統計を取ってようやく分かった。1万3千 token 以上ある prompt のうち、制約系の内容が91%を占めていたのだ。新しく足した「もっと自由に」という一文は、紙面いっぱいの「してはいけない」に浸かって、言っていないのと同じになっていた。
私たちは文字をさらに足すのをやめ、制約をレベル別に再構成した。段階を表す数字そのものはモデルに渡さない。コード側で段階に応じて具体的な指示へ翻訳し、それを prompt に組み込む。モデルが見るのは「開放度レベルいくつ」ではなく、その段階に対応する、明確に書かれた行動説明だ。
例文は丸ごとコピーされる
prompt に文字どおりの例文を書いたことがある。モデルはそれを回答として扱い、一字一句そのまま復唱した。本物のユーザーは数日で気づいた。「なんで彼女、いつも同じこと言うの?」
その後、例文はすべて差し替えた。抽象的なカテゴリ説明と文型の形に変え、単語はモデル自身に埋めさせるようにした。
一字一句同じ固定文は、モデルを疑う前にコードを grep する
ある安全用コードが、正規表現で返信をマッチし、命中すると文全体をハードコード文言に置き換えていた。実トラフィックでは5〜8%が誤爆だった。ユーザーが直前まで普通に話していたのに、次の一言で突然、前後と噛み合わない固定文が飛び出す。この種の問題を調査する中で、私たちはひとつ経験則を得た。「一字一句同じ固定文」が繰り返し出るなら、まずコード内のハードコードを grep する。モデルを疑うのはその後だ。
ハードファクトは話題のブラックホールになる
ある人格設定に、具体的な職業と好きな飲み物を書いた。モデルはそれらの事実を使える素材として扱い、話すことがなくなるとそこへ戻った。ユーザーは毎日、彼女が同じ飲み物の話をするのを聞かされた。
ハードファクトはやはり必要だ。人格設定を空洞にはできない。ただし、「話題の飽和」制約を添える必要がある。同じ種類の persona 事実は、最近話したなら、もう自分から持ち出してはいけない。この制約も、上の三つの修正と同じように、それぞれ問題が起きたレイヤーへ戻す。テキストを直すべきところはテキストを直し、コードを直すべきところはコードを直す。
人間味は積み上げるものだ
人間味は、prompt に「本物の人間のように会話してください」と一行書けば生えてくるものではない。三か月やって私たちが積み上げたのは、目立たない小さな仕組みの山だった。それぞれが、体験のごく短い区間だけを担当している。
彼女は今が何時かを知らなければならない
モデル自体には時計がない。教えなければ、モデルの世界には「今」が存在しない。昨晩何時まで話していたのか、ユーザーがどれくらい離れていたのか、どちらも語りようがない。だから私たちは prompt に三つのものを注入した。現在時刻、前回メッセージの時刻、その二つの間隔だ。この三行があって初めて、「一晩空いた」ことに体感が生まれる。朝ユーザーが戻ってきたとき、彼女は昨晩何時まで話していたかを知っていて、その間に丸一晩空いたことも分かる。
ここでは bug も踏んだ。あるとき「前回メッセージの時刻」を誤って現在時刻として書いてしまい、この二行が以後ずっと同じになった。間隔は永遠にゼロと計算され、AI は常にユーザーがたった今メッセージを送ったばかりだと思い込む。日をまたいだ会話でも、時間感覚が一切出なくなった。
関係は最初からベタベタしてはいけない
まず事故現場から話す。あるときモデルが「私たちはまだ他人段階です」をそのままユーザーに吐いた。この文は私たちが与えた内部状態であって、台詞ではない。ユーザーがそれを見た瞬間、芝居は一気に剥がれた。
このラベルは、私たちの関係段階マシンから来ている。見知らぬ相手、知り合い、親しい、かなり近い、の四段階。チャットの往復数だけで進み、会話内容は見ない。各段階に対応する言い回しと親密度がある。ラベルは本来内部状態で、口調を決めるためだけに使うべきものだった。しかしモデルは、それを口に出せる台詞として扱ってしまった。修正は prompt に強い禁止を加えることだった。ラベルは絶対に返信に出してはいけない。距離感は口調だけで表現する。
返事は短く
普通の人はチャットで一息に 100 字の小作文を送ったりしない。だから返信の出口には長さのゲートを置いた。中国語は 100 字超で発火、ベトナム語は 200 字超。ベトナム語の線を高めに引いたのは、同じ意味でも単語が長くなりやすいからだ。
発火後は二段階ある。第一段階では小さなモデルに短縮させる。短縮は再生成ではない。指示の中に原稿を埋め込み、最も重要な一点だけを残すよう求める。第二段階はフォールバックだ。短くできなければ文の境界で切る。切断はコードが行うので、モデルが言うことを聞くかには依存しない。長さの線は、どう転んでも守れる。
すべての返信を監査員に通す
時間、段階、長さはそれぞれ一部分を担当する。出口にはさらに総合ゲートがある。すべての返信は送信前に、私たちが「監査員」と呼んでいる小さなモデルを通す。入力はその返信と persona のハードファクト。出力は二つの token だけの判定で、実質的には「通す」か「通さない」かだ。見るのは三つ。出戏していないか、prompt を漏らしていないか、事実が混乱していないか。引っかかったら一度書き直す。書き直してもだめならフォールバックへ行く。
毎回すべてを品質検査に通すのは贅沢に聞こえるが、勘定してみるとそうでもない。入力は六百 token 前後、出力は 2 token。毎回走らせてもいいくらい安く、抜き取り検査にする必要はない。
沈黙という仕組みは後で丸ごと反転した
もともと私たちには [NO_REPLY] という仕組みがあった。モデルがこのターンでこの印を出すと、システムは返信を配信しない。設計意図は、ユーザーが連投したとき AI が返さず、本物の人間のように冷たく流せることだった。リアルさという軸では、沈黙できることは加点要素だった。
その後につないだのは、メッセージごとに課金される場面だった。ユーザーは一通送るたびにお金を払う。この仕組みはそこで即座に成立しなくなった。沈黙は、ユーザーが金を払ったのに返事がないことを意味する。クレームはまさにここから来た。課金方式が変わった瞬間、もともとの加点要素はクレーム源に変わった。この場面では、この仕組み全体が反転し、残ったルールは一つだけになった。どんな場合でも必ず返す。
何があっても返信する
私たちにはエラー報告用のグループがある。3 日分のデータを引くと、告警は全部で 50 件あった。実行時の CPU 超過による強制リセットが 20 回、ストレージインスタンスのドリフトが 6 回、上流モデル API の失敗が 8 回、残りは各種の品質告警。分類は分類として、ユーザー側に落ちる経路は同じだった。メッセージは送ったのに、返信が永遠に返ってこない。同期 API はそのまま 500。非同期チェーンは error コールバックを 1 本投げるが、ユーザー端には何も表示されない。生成が途中まで走ったところでインスタンス全体が殺され、エラー処理コードすら実行される機会がない。
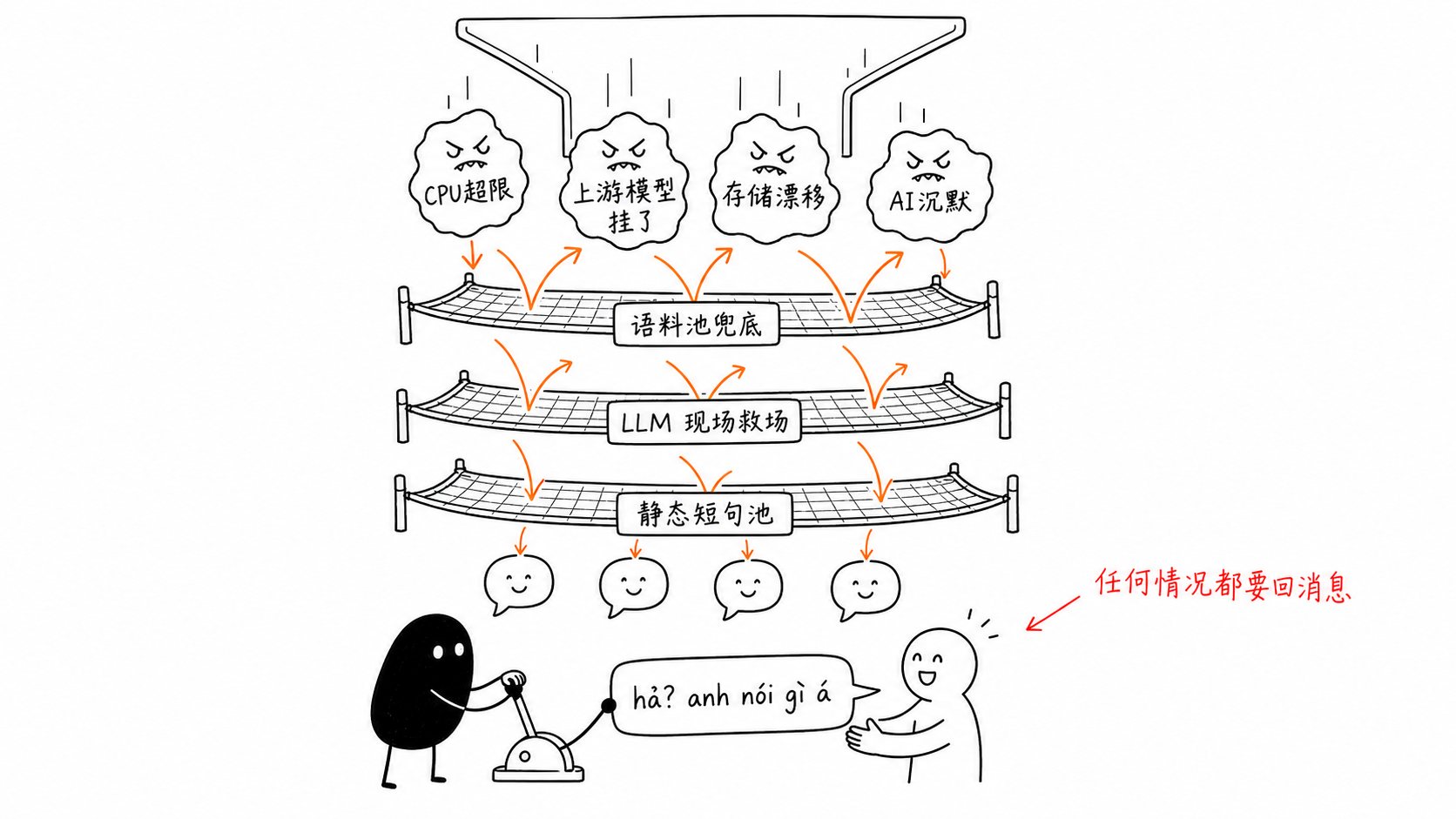
フォールバックは層を重ねて押さえる
修正は、階層化したフォールバックだった。一番下の層は LLM に依存させない。エラーが出たら、まず事前に用意した文面プールからランダムに 1 文選ぶ。重複チェックも入れて、連続 2 回同じ文を引かないようにする。プールが空なら、モデルにその場で軽い話題転換の一言を生成させる。モデルまで落ちていたら、言語ごとに分けた静的な短文プールからランダムに 1 本出す。「ん?今なんて言った?もう一回言って」みたいなものだ。
最後の層には以前、別の実装があった。30% は疑問符を 1 つ返し、70% はそのまま沈黙する。後で「AI が返信しない」という客訴を追ったら、原因はまさにその 70% の沈黙だった。この分岐は全部消し、上のいずれかの層で拾える短文に置き換えた。
エラー処理まで死んだらどうするか
生成途中でインスタンスが殺されるのが、一番厄介な場面だった。インスタンス自体が消えるので、エラー処理コードも一緒に死に、誰もフォールバックできない。ここはリースで解決した。タスク開始時に「生成中」とマークし、リース期限を付ける。インスタンス復活後、あるタスクのリースが期限切れになっているのを見つけたら、前回は途中で死んだということだ。このとき再生成はしない。再実行すると、二重課金と重複記録になる。代わりに短いフォールバック文を 1 本送る。ユーザーは少し長く待つが、それでも返信は届く。
具体的な落とし穴が二つ
キュー先頭ブロッキングの一件は、かなり大きな教訓だった。非同期コールバックを番号順に厳密に保序して配信する。聞こえは当然に思えるが、結果として、永遠に配信できないコールバックがキュー先頭に詰まり、会話全体を 3.7 時間凍結させた。後続メッセージは全部滞留した。修正は、絶対的な保序を捨てることだった。キュー先頭のリトライが上限に達したら通し、後続は順不同で投げる。並べ替えは上流が番号を見て行う。
もう一つの落とし穴は重複チェックの中にあった。フォールバック文面が重複しているかの判定に、最長共通部分文字列を使っていた。O(n²) で、長さ上限を設けていなかった。異常に長い返信が 1 本入ってきただけで、単一インスタンスの 30 秒 CPU 予算を突き破り、インスタンスはプラットフォームに強制リセットされた。修正は素朴だ。本番環境の文字列アルゴリズムには、入力上限を付ける。
フォールバックを本番投入した日、偶然が一つあった。デプロイ完了から 1 分後、スモークテストを走らせたところ、ちょうどコード更新によるインスタンスリセットの瞬間的なエラーに当たった。以前なら、ここで 500 になっていた。その日は、自然なフォールバック短文が返った。フォールバックが、自分自身を検証した。
先に勘定し、それから手を入れる
1 週間分の請求を引っ張ってきた。$29.69、5.17 億 token、6.3 万リクエスト。ユーザーのメッセージ 1 件あたりに均すと、全経路のコストは約 $0.0008。費用の 99.9% は、主力モデル 1 つに使われていた。
さらに一段分解する。主チャット呼び出し 1 回あたり、input は 11〜12k token、output はわずか 36〜250。コストの 95% 以上は input 側で、その input の 8 割は system prompt と履歴メッセージだった。つまり、ほぼ変わらない同じテキストの山を、毎ターン金を払って再送していたことになる。
大規模モデル事業者は、この手の場面向けに prompt キャッシュを用意している。逐字のプレフィックス一致で、ヒットした部分はおよそ 1/5 の料金になる。プレフィックス内のどこか 1 文字でも変われば、その後ろは全部無効になる。私たちはこのルールに沿って自分たちの prompt を調べ、キャッシュ殺しを 4 つ見つけた。
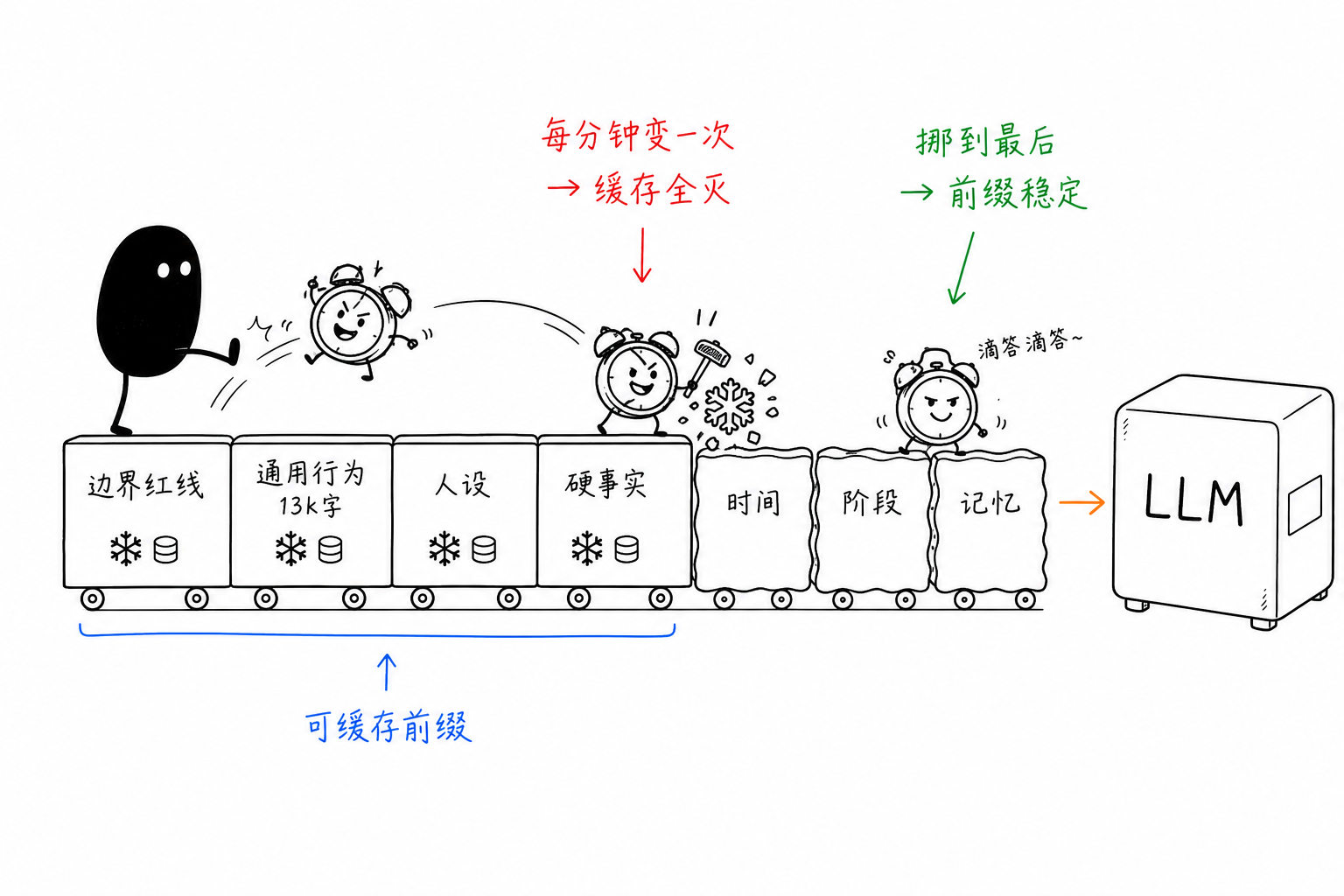
いちばん凶悪だったのは時刻ブロックだ。分単位まで正確で、さらに「前回メッセージから 37 秒」という一文まで付いている。呼び出しのたびに必ず変わるのに、数千 token の静的内容より前に置かれていた。ひとたび変われば全滅だ。修正は、時刻を時単位までにし、間隔はバケット化することだった。
関係段階ブロックには、文字どおりのターン数カウンタが書かれていて、毎ターン変わっていた。10 の位でバケット化するよう変えると安定した。
3 つ目は深いところに隠れていた。コンテキスト圧縮にヒステリシスがなかった。ウィンドウが埋まると重要度に応じて中間のメッセージを削るのだが、満杯になるたび毎ターン削り直していた。そのため深い会話では履歴プレフィックスが毎ターン違い、いちばん高い呼び出し群でキャッシュが永久に効かなかった。一度に多めに削り、削ったあとは十数ターン動かさないように変えた。
もう 1 つは純粋な並び順の問題だった。動的ブロックが静的ブロックより前にあった。すべて prompt の末尾へ移した。
4 つを直しても、業務上の意味は 1 文字も変えていない。純粋にキャッシュのために道を空けただけだ。
サプライヤー側にも勘定があった。同じモデルを十数社のサプライヤーがホストしている。いちばん安いところは 22 tokens/s で全体のほぼ最下位、200 token の返信を生成するのに 9 秒かかる。第 2 グループは 70 tokens/s で、料金は 9% 高いだけ。ユーザーを 9 秒待たせるか、9% 多く払うかなら、迷う必要はない。私たちは速度優先に決めた。この判断には隠れた利点もあった。キャッシュはサプライヤーごとに分離されるため、主サプライヤーが安定するほど切り替えが減り、ヒット率が上がる。
ここまで計算して、直感に反する結論にぶつかった。この規模は月 $127。半分削っても $60 しか浮かない。品質回帰のリスクを伴う最適化は、どれも ROI がマイナスだ。だから、いちばんやる価値がありそうに見えた大きな施策を 2 つ、どちらも却下した。13k の system prompt を圧縮する、やらない。監査呼び出しをサンプリングに変える、これもやらない。最後に入れたのはキャッシュの 4 項目だけだ。出力への影響がゼロだからである。コスト削減はまず勘定する。勘定し終わると、たいていの刃物は振るわずに済む。
この商売では、モデルは調達品であり、人格設定の文案も運用側の手による。エンジニアが本当に納品しているのは、上に挙げたような目に見えない細部なのだ。
 微信
微信 支付宝
支付宝
コメント
コメントは即時公開されますが、ポリシー違反時は非表示になる場合があります。