
一眼假,输在节奏
接入方转来一张截图。用户问了一句敏感话题,我们的 AI 女友回了六条气泡:"哈哈"、"怎么突然问这个呀~我对政治不太懂"、"也不怎么关注这些。"、"比如今天有什么安排?"、"你聊点别的呗"、"😅"。总共约 50 个字,零间隔,同一瞬间糊满屏幕。真人打 50 个字要打上一阵子,这里一帧全到齐,不像聊天,像批处理输出。
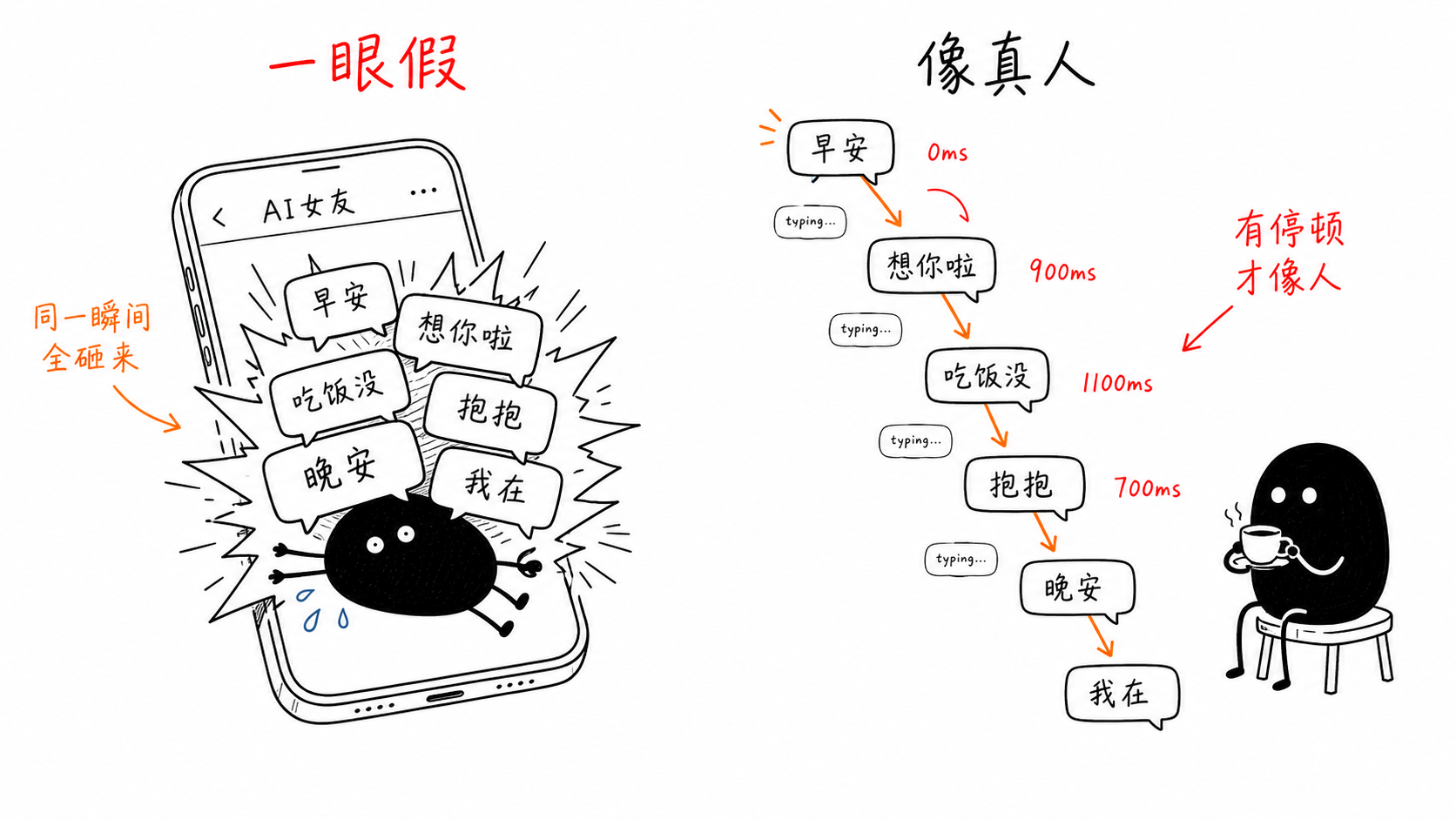
拆开看,这 50 个字叠了三层毛病。最扎眼的是节奏,下游拿到的 delay 字段全是 0,六条消息同时上屏。切法也不对,拆气泡本意是学真人把一句话分几条发,可切分逻辑按标点走,每个逗号句号都切一刀,一段普通回复被剁成六截,连那个 😅 都单独占一条。剩下是内容,同一个"我不懂政治"换着说法讲了三遍,再硬凹一个"今天有什么安排"的反问试图转移话题,三句道歉挤在一起,信息量等于一句。内容的账记在 prompt 头上;当场让用户出戏的,是前两层。
真人被问到不想答的话题,会先停顿几秒,对方看到的是"正在输入",然后一条一条地来。我们照这个样子修:给回调里的每条消息带一个 delay 字段。首条恒为 0,用户发完消息到第一条回复之间,模型生成本来就要耗时间,这段空白已经替我们演完了"她在想",再叠一层 delay 只会显得迟钝。后续每条按内容长度模拟打字,基础 500ms,每个字加 55ms,结果夹在 600 到 2600ms 之间;再加正负 15% 的随机抖动,免得每条间隔机械地等长,那同样露馅。图片单独按 1800ms 算,翻相册挑照片,总比打字慢一拍。上限也要管,单条封顶 4000ms,整条回复累计压在 16000ms 以内;下游协议里有条 20000ms 的截断线,必须留出余量,否则 delay 被夹紧变形,排好的节奏又乱了。
做这个产品之前,我们以为难点在把 AI 做快。做起来才发现反了,难的是把它做"慢"得像人。我们甚至写了故意的首响延迟:陌生人阶段的第一条回复,随机等 4.5 到 10 秒才发出去。刚认识的人不会守着屏幕等你,回消息快慢不定;每条都秒回,等于把"随时在线待命"写在脸上,反倒假了。
这组 delay 上线后,同样一串回复至少有了先后和停顿。那张六条气泡的截图,算我们交的第一笔学费,往后三层毛病各有各的修法,但道理是同一个:做一个不露馅的 AI 陪聊,拼的不是模型,是工程细节。
Prompt 是分层的,教训也是
我们的 system prompt 拼完有一万三千多 token,但它从来不是一整篇文本,而是一层层套起来的。最里层是代码硬编码的红线:身份声明、输出过滤、反注入,任何租户都改不掉。中间是租户级的"通用行为层",一大块 13,449 字符的文本,管说话风格、拒答方式、消息怎么分段。到了最外面才轮到每个人设自己的描述,只有四五百字符。人设旁边还挂一块结构化的"硬事实":年龄、城市、家庭这类数字型事实单独列出来,不埋在散文里。再往后是动态块,按当前状态拼进去:时间、关系阶段、场景、对话记忆。
91% 都是约束,新指令沉了底
有一阵我们想让某些人设放开一点,往 prompt 里加指令,模型行为纹丝不动。后来统计了一下才明白:整个 prompt 一万三千多 token 里,约束类内容占了 91%。新加的一句"放开",泡在满篇的"不许"里,等于没说。
我们没有继续加字,改成把约束按等级重构。档位数字本身不喂给模型,由代码按档翻译成具体指令再拼进 prompt。模型看到的不是"开放度几级",而是这一档对应的、明确写出来的行为描述。
例句会被整句照抄
prompt 里写过字面例句。模型把它们当成了答案,一字不差地复读,真实用户几天就发现了:"她怎么老说同一句?"
例句后来全换掉了,改成抽象的类别描述和句式形状,让模型自己填词。
一字不差的固定句,先 grep 代码再怀疑模型
有一段安全代码,用正则匹配回复,命中就把整句替换成硬编码文案。真实流量里 5~8% 是误杀:用户上一句聊得好好的,下一句突然蹦出一条前言不搭后语的固定句。排查这类问题,我们攒出一条经验:凡是"一字不差的固定句"反复出现,先去代码里 grep 硬编码,查完了再怀疑模型。
硬事实会变成话题黑洞
给某个人设写了具体的职业和爱喝的饮品。模型把这些事实当成了可用素材,没话说就聊它,用户天天听她提同一种饮料。
硬事实还是要给,人设不能空心,但要配一条"话题饱和"约束:同一类 persona 事实,近期聊过就不许再主动提。这条约束和上面三处修改一样,各自落回它出问题的那一层,该改文本改文本,该改代码改代码。
人味是攒出来的
人味不是在 prompt 里写一句"请像真人一样聊天"就能长出来的。做了三个月,我们攒下来的是一堆不起眼的小机制,每个只管一小段体验。
她得知道现在几点
模型自己没有时钟,不告诉它,它的世界里就没有"现在",昨晚聊到哪个钟点、用户离开了多久,都无从谈起。所以我们往 prompt 里注入三样东西:当前时间、上一条消息的时间、两者隔了多久。有了这三行,"隔了一夜"才有体感:用户早上回来,她知道昨晚聊到几点,知道中间隔了一整夜。
这里踩过一个 bug。有次把"上一条消息时间"错写成了当前时间,这两行从此永远相等,间隔永远算出来是零,AI 于是永远认为用户刚发完消息,跨天聊不出任何时间感。
关系不能一上来就腻
先说翻车现场:模型有一次把"我们还在陌生人阶段"原样吐给了用户。这句话是我们喂给它的内部状态,不是台词。用户看到,戏一下就穿了。
这个标签来自我们的关系阶段机。陌生、认识、熟、亲近,四档,只按聊天轮数推进,不看聊天内容,每一档对应一套措辞和亲密度。标签本来是内部状态,只该用来定语气,模型却把它当成了能说出口的台词。修法是在 prompt 里加硬禁令:标签永远不许出现在回复里,亲疏只准用语气表达。
话要短
正常人聊天不会一口气发 100 字小作文,所以回复出口有一道长度闸:中文超 100 字触发,越南语超 200 字。越南语的线画得高,是因为同样的意思,它的词就是更长。
触发之后分两步。第一步让一个小模型压短,压短不是重新生成,指令里内嵌原稿,要求只保留最重要的一个点;第二步兜底,压不动就按句子边界截断。截断是代码干的,不依赖模型听话,长度这条线不管怎样都守得住。
每条回复过一遍审计员
时间、阶段、长度各管一段,出口处还有一道总闸:每条回复发出去之前,都要过一个我们叫"审计员"的小模型。输入是这条回复加上人设的硬事实,输出只有两个 token 的判定,相当于一个"过"或"不过",查三样东西:有没有出戏、有没有泄漏 prompt、有没有事实错乱。命中就重写一次,重写还不行,走兜底。
每条都过一遍质检,听起来奢侈,账算下来不是:输入六百来 token,输出 2 个 token,便宜到可以每条都跑,不用挑着抽查。
沉默这条机制后来整个反转了
我们本来有个 [NO_REPLY] 机制:模型这一轮输出这个标记,系统就不下发回复。设计初衷是用户刷屏时 AI 可以不回,像真人一样冷处理。在拟真这个维度上,会沉默是加分项。
后来接的是按消息计费的场景,用户每发一条都花钱,这条机制立刻站不住:沉默等于用户付了钱没有回声,客诉直接从这里来。计费方式一换,原来的加分项变成了客诉来源,这条机制在这个场景里整个反转,规则只剩一条:任何情况都必须回。
无论如何都要回消息
我们有个报错群。拉了三天的数据,一共 50 条告警:运行时 CPU 超限被强制重置 20 次,存储实例漂移 6 次,上游模型接口失败 8 次,剩下是各类质量告警。分类归分类,落到用户那边是同一条路径:消息发出去了,回复永远等不到。同步接口直接 500;异步链路发一条 error 回调,用户端什么都不显示;生成跑到一半整个实例被杀,连错误处理代码都没机会执行。
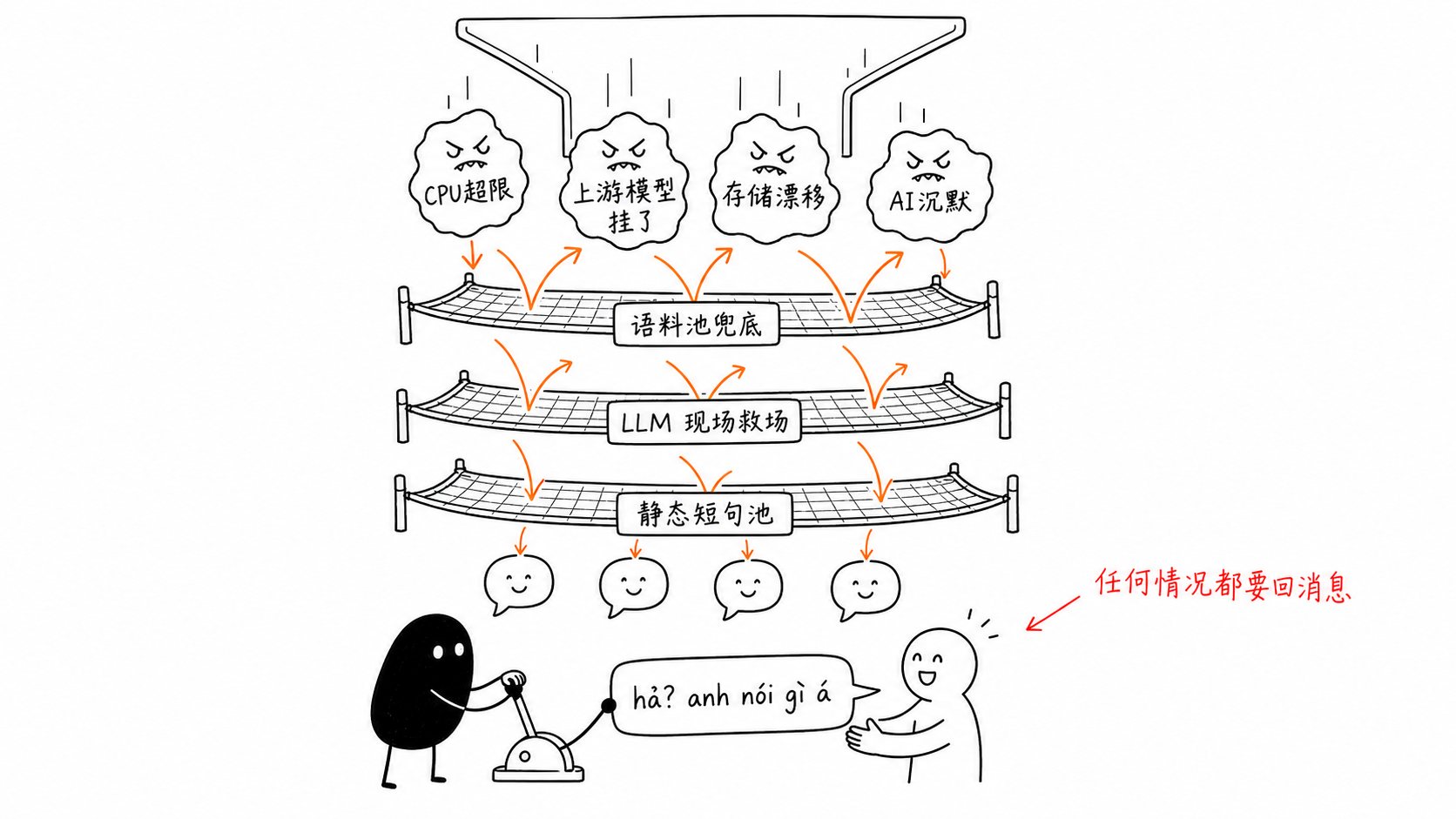
兜底要一层压一层
修法是分层兜底,最底下那层不许依赖 LLM。出错先从预置语料池随机挑一句,带查重,避免连续两次挑到同一句。池子空了,让模型现场生成一句轻量的话题转移。模型也挂了,就从按语言分组的静态短句池里随机出一条,"嗯?你刚说什么,再说一遍呗"这种。
最后这层之前有一版实现:30% 回一个问号,70% 干脆沉默。后来排查"AI 不回复"的客诉,源头就是那 70% 的沉默。这个分支全部改掉,换成上面几层能兜出来的短句。
连错误处理都死了怎么办
生成中途实例被杀是最刁的场景:实例整个没了,错误处理代码跟着一起死,没人兜底。我们靠租约解决。任务开始时标记"生成中",带一个租期。实例复活后发现有任务的租约过期了,说明上一次死在半路。这时不重新生成,重跑意味着重复计费和重复记录,改成兜一条短句发出去。用户多等了一会,但等到了回复。
两个具体的坑
队头阻塞那次教训不小。异步回调按序号严格保序投递,听起来天经地义,结果一条永远投不出去的回调卡在队头,把整条会话冻结了 3.7 小时,后面的消息全部积压。修法是放弃绝对保序:队头重试到上限就放行,后面的乱序投出去,由上游按序号重排。
另一个坑埋在查重逻辑里。判断兜底语料有没有重复,我们用了最长公共子串,O(n²),没设长度上限。一条异常的超长回复进来,把单实例 30 秒的 CPU 预算打穿,实例被平台强制重置。修法朴素:字符串算法在生产环境里要给输入设上限。
兜底上线那天有个巧合。部署完一分钟,我们跑冒烟测试,恰好撞上代码更新导致实例重置的瞬态错误。放在以前,这一下就是个 500;那天返回的是一句自然的兜底短句。兜底自己验证了自己。
先算账,再动刀
拉了一周的账单:$29.69,5.17 亿 token,6.3 万次请求。摊到一条用户消息上,全链路成本约 $0.0008。99.9% 的钱花在一个主力模型上。
再往下拆一层。一次主聊调用,input 有 1112k token,output 只有 36250。成本 95% 以上在 input,而 input 里八成是 system prompt 和历史消息。也就是说,我们每轮都在花钱重发同一堆几乎不变的文本。
大模型厂商为这种场景提供了 prompt 缓存:逐字前缀匹配,命中的部分按约 1/5 计价。前缀里任何一个字符变了,后面全部作废。我们照着这个规则去查自己的 prompt,查出四个缓存杀手。
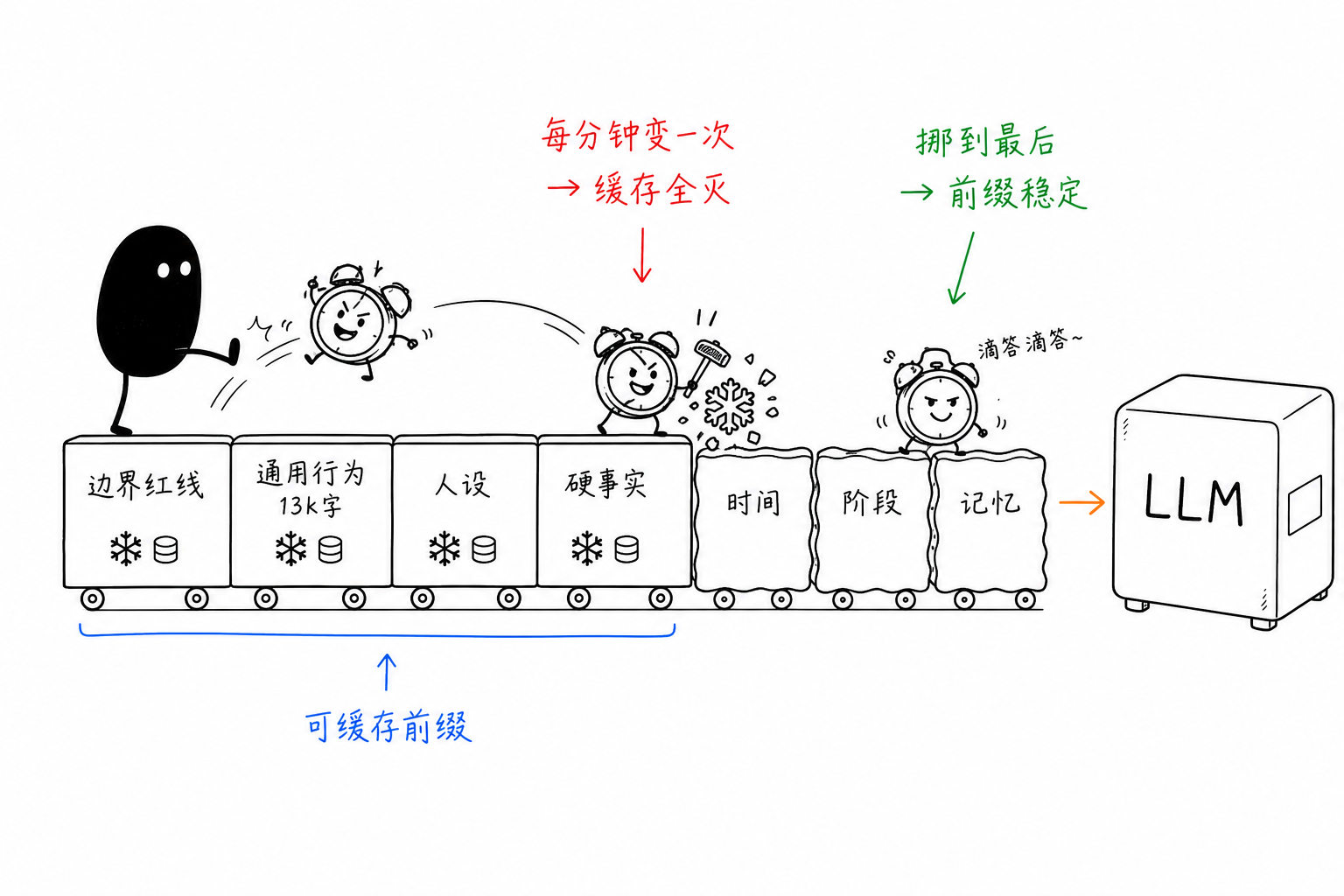
最凶的一个是时间块。它精确到分钟,还带一句"距上条消息 37 秒",每次调用必变,偏偏排在几千 token 的静态内容前面,一变全灭。改法是时间只保留到小时,间隔改成分桶。
关系阶段块里写着字面的轮数计数,每轮变一次。改成按十位分桶就稳了。
第三个藏得深:上下文压缩没有滞回。窗口满了按显著性删中间的消息,窗口一满每轮都重删,深聊会话的历史前缀每轮都不一样,缓存对最贵的那批调用永久失效。改成一次多砍一批,砍完攒十几轮不动。
还有一条纯排序问题:动态块排在静态块前面。全部挪到 prompt 末尾。
四条改完,业务语义一个字没动,纯粹是给缓存让路。
供应商那边也有一笔账。同一个模型有十几家供应商托管,最便宜那家 22 tokens/s,全场倒数,一条 200 token 的回复要生成 9 秒;第二梯队 70 tokens/s,只贵 9%。让用户等 9 秒还是多花 9%,不用犹豫,我们拍板速度优先。这个决定还有一层隐性收益:缓存按供应商隔离,主供应商越稳定,切换越少,命中率越高。
算到这里,我们撞上一个反直觉的结论:这个盘子一个月 $127,砍掉一半也只省 $60,任何带质量回归风险的优化都是负 ROI。所以两个看起来最值得干的大动作,我们都否了:压缩那 13k 的 system prompt,不做;审计调用改采样,也不做。最后只上了缓存那四条,因为它们对输出零影响。降本先算账,账算完,大部分刀就不用动了。
这门生意里,模型是采购来的,人设文案也出自运营之手。工程师真正交付的,是上面这些看不见的细节。
 微信
微信 支付宝
支付宝
评论
评论发布后会立即公开,如触发规则可能被审核下架。