
Obviously Fake, Because the Rhythm Is Wrong
An integration partner sent over a screenshot. A user had asked about a sensitive topic, and our AI girlfriend replied with six chat bubbles: “Haha,” “Why are you suddenly asking about that~ I don’t really understand politics,” “I don’t really follow that stuff either,” “So, what are your plans today?” “Talk about something else,” and “😅”. About 50 characters in total, with zero spacing, all flooding the screen at the same instant. A real person would take a while to type 50 characters. Here, everything arrived in one frame. It did not feel like chatting; it felt like batch output.
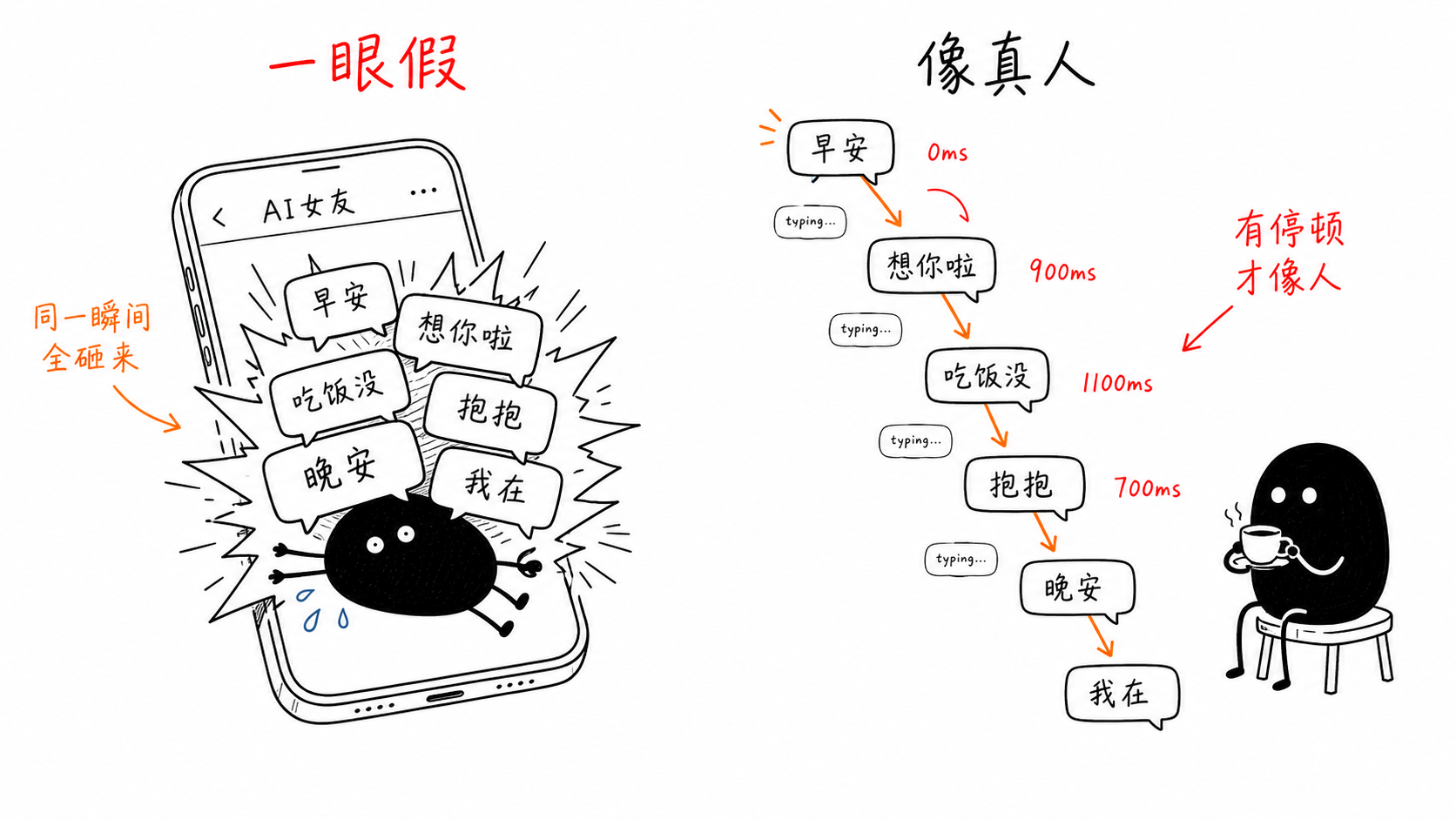
Breaking it down, those 50 characters had three layers of problems. The most glaring was rhythm: every message the downstream system received had a delay field of 0, so all six messages appeared on screen at the same time. The splitting was wrong too. The point of splitting bubbles was to imitate how real people send one thought across several messages, but the splitting logic followed punctuation, cutting at every comma and period. An ordinary reply was chopped into six pieces, and even the 😅 got its own separate bubble. The rest was content: the same “I don’t understand politics” was repeated three different ways, followed by a forced “what are your plans today” question trying to change the subject. Three apologies were packed together, and the amount of information was equivalent to one sentence. The content issue belongs to the prompt. What made the user immediately break immersion was the first two layers.
When a real person is asked about something they do not want to answer, they first pause for a few seconds. The other person sees “typing,” and then the replies arrive one by one. We fixed it by following that pattern: each message in the callback gets a delay field. The first message is always 0. After the user sends a message, model generation already takes time before the first reply appears, and that blank space has already performed the role of “she is thinking” for us. Adding another delay on top would only make her seem sluggish. For subsequent messages, we simulate typing based on content length: a base of 500 ms, plus 55 ms per character, clamped between 600 and 2600 ms. Then we add a random jitter of plus or minus 15%, so the intervals do not become mechanically identical, which would also give the game away. Images are handled separately at 1800 ms. Looking through an album to pick a photo should be a beat slower than typing. The upper bounds also need control: a single message is capped at 4000 ms, and the cumulative delay for the whole reply is kept within 16000 ms. The downstream protocol has a 20000 ms cutoff line, so we have to leave margin. Otherwise, the delays get clamped and distorted, and the carefully arranged rhythm falls apart again.
Before building this product, we thought the hard part would be making the AI fast. Once we actually built it, we realized it was the opposite: the hard part was making it “slow” in a human way. We even wrote an intentional first-response delay: for the first reply during the stranger stage, it waits a random 4.5 to 10 seconds before sending. Someone you just met will not be sitting there staring at the screen waiting for you. Reply speed varies. If every message gets an instant reply, it is like writing “online and on standby at all times” across her face, which makes it feel fake instead.
After this delay system went live, the same string of replies at least had order and pauses. That screenshot of six chat bubbles was the first tuition we paid. The next three layers of problems each had their own fixes, but the principle was the same: building an AI chat companion that does not break immersion is not about the model; it is about engineering details.
Prompts Are Layered, and So Are the Lessons
Our system prompt ended up with more than 13,000 tokens, but it was never one single block of text. It was nested layer by layer. At the innermost layer were the hard-coded red lines in code: identity declarations, output filtering, anti-injection rules. No tenant could change them. In the middle was the tenant-level "general behavior layer": a large 13,449-character block of text that governed speaking style, refusal patterns, and how messages should be split. Only at the outermost layer did each person get to set their own description, usually just four or five hundred characters. Next to the persona sat a structured block of "hard facts": age, city, family, and other numeric facts were listed separately instead of being buried in prose. After that came dynamic blocks, assembled according to the current state: time, relationship stage, scene, and conversation memory.
91% Was Constraints, So New Instructions Sank to the Bottom
For a while, we wanted to make certain personas a little more open, so we added instructions to the prompt, but the model's behavior did not budge. Later, after doing the numbers, we understood why: across the more than 13,000 tokens in the full prompt, constraint-type content accounted for 91%. One new sentence saying "loosen up," soaked in a page full of "do nots," was the same as saying nothing.
We did not keep adding more words. Instead, we restructured the constraints by level. The level number itself was not fed to the model; code translated each level into concrete instructions and then assembled them into the prompt. What the model saw was not "openness level X," but the explicit behavioral description corresponding to that level.
Example Sentences Get Copied Verbatim
We had once written literal example sentences into the prompt. The model treated them as answers and repeated them word for word. Real users noticed within days: "Why does she keep saying the exact same thing?"
Those examples were later replaced entirely with abstract category descriptions and sentence-shape guidance, leaving the model to fill in the words itself.
For Verbatim Fixed Phrases, Grep the Code Before Blaming the Model
There was a piece of safety code that used regex to match replies. When it hit, it replaced the entire sentence with hard-coded copy. In real traffic, 5–8% of cases were false positives: the user had been chatting normally in the previous message, and then the next reply suddenly dropped a fixed sentence that had nothing to do with the context. From debugging problems like this, we learned one rule: whenever a "verbatim fixed phrase" keeps appearing, grep the code for hard-coded strings first, and only suspect the model after that.
Hard Facts Can Become Topic Black Holes
We wrote a specific job and favorite drink for one persona. The model treated those facts as usable material. Whenever it had nothing else to say, it talked about them, so users heard her mention the same drink every day.
Hard facts still need to exist; a persona cannot be hollow. But they need to come with a "topic saturation" constraint: if the same type of persona fact has been discussed recently, the model is not allowed to bring it up again proactively. Like the three changes above, this constraint had to land back in the layer where the problem originated: change text where text should be changed, and change code where code should be changed.
Human Flavor Is Accumulated
Human flavor does not grow out of writing “please chat like a real person” in the prompt. After three months of work, what we accumulated was a pile of small, unremarkable mechanisms, each responsible for only a tiny slice of the experience.
She Has to Know What Time It Is
The model has no clock of its own. If you do not tell it, there is no “now” in its world; there is no way to talk about what time the conversation ended last night, or how long the user was gone. So we inject three things into the prompt: the current time, the time of the previous message, and how much time has passed between the two. With these three lines, “a night has passed” finally becomes something it can feel: when the user comes back in the morning, she knows what time they talked until last night, and knows that a whole night passed in between.
We hit a bug here once. At one point, “previous message time” was accidentally written as the current time. From then on, the two lines were always equal, the interval was always calculated as zero, and the AI forever thought the user had just sent a message. Cross-day conversations had no sense of time at all.
The Relationship Cannot Be Clingy From the Start
First, the crash scene: one time, the model literally said “we are still in the stranger stage” to the user. That sentence was an internal state we fed to it, not a line of dialogue. The moment the user saw it, the illusion broke.
That label came from our relationship-stage machine. Stranger, acquainted, familiar, close: four levels, advancing only by number of conversation turns, not by conversation content. Each level corresponds to a set of wording choices and a degree of intimacy. The label was meant to be internal state, only used to decide tone, but the model treated it as something it could say out loud. The fix was to add a hard ban in the prompt: labels must never appear in replies; closeness and distance may only be expressed through tone.
Replies Have to Be Short
Normal people do not send 100-character mini-essays in one breath when chatting, so there is a length gate at the output: over 100 Chinese characters triggers it, and over 200 Vietnamese characters triggers it. The Vietnamese threshold is higher because the same meaning simply takes longer words.
Once triggered, it happens in two steps. First, a small model compresses the reply. Compression is not regeneration: the original draft is embedded in the instruction, and the model is asked to keep only the single most important point. Second, there is a fallback: if it cannot compress it, the reply is truncated at sentence boundaries. Truncation is done by code, not by relying on the model to obey. No matter what, the length line can be held.
Every Reply Goes Through an Auditor
Time, stage, and length each handle one slice. At the exit, there is one more master gate: before every reply is sent, it must pass through a small model we call the “auditor.” The input is the reply plus the hard facts of the persona. The output is only a two-token judgment, effectively “pass” or “fail,” checking three things: whether it breaks character, whether it leaks the prompt, and whether the facts are inconsistent. If it hits, we rewrite once; if the rewrite still fails, we use the fallback.
Running QA on every single reply sounds extravagant, but the math says otherwise: around six hundred input tokens and 2 output tokens. Cheap enough to run on every message, no need to sample selectively.
The Silence Mechanism Later Completely Flipped
We originally had a [NO_REPLY] mechanism: if the model output this marker in a turn, the system would not send a reply. The design intent was that when users spammed messages, the AI could choose not to answer, cold-processing it like a real person. In terms of realism, being able to stay silent was a plus.
Later, this was connected to a per-message billing scenario. Every message the user sent cost money, so this mechanism immediately became untenable: silence meant the user paid and got no response, and complaints came directly from there. Once the billing model changed, the original plus became a source of complaints. In this scenario, the mechanism completely flipped, leaving only one rule: it must reply under all circumstances.
Reply No Matter What
We have an error-reporting group. Pulling three days of data gave us 50 alerts in total: 20 forced resets due to runtime CPU limits, 6 storage instance drifts, 8 upstream model API failures, and the rest were various quality alerts. Classification is classification, but from the user's side they all collapse into the same path: the message was sent, and the reply never arrived. The synchronous API returned a straight 500; the async pipeline sent an error callback, but nothing showed on the user side; generation got halfway through and the whole instance was killed, leaving no chance for even the error-handling code to run.
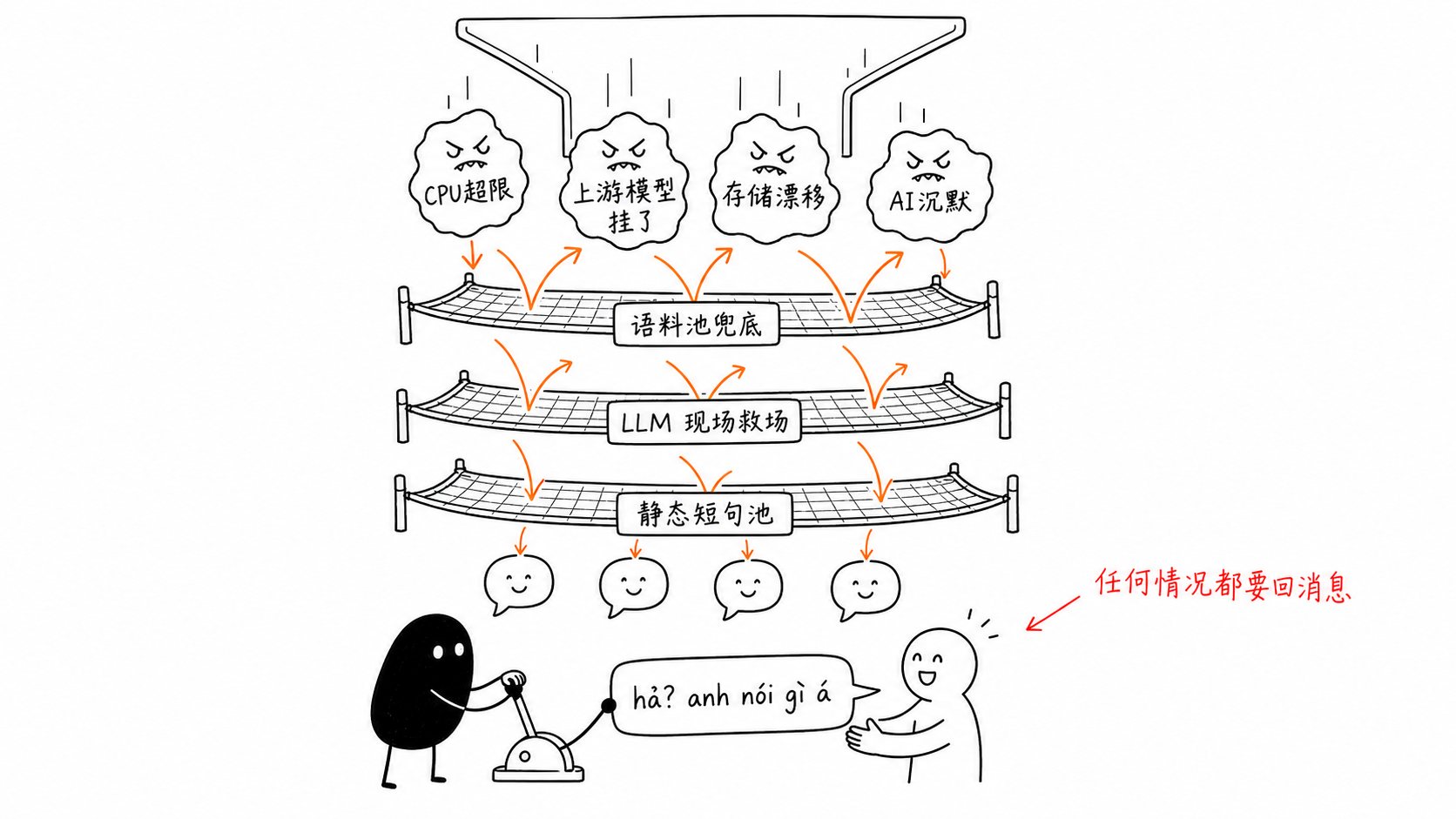
Fallbacks Have to Stack Layer by Layer
The fix was layered fallback, with the bottom layer not allowed to depend on the LLM. When an error happens, first randomly pick a sentence from a preset copy pool, with deduplication to avoid picking the same sentence twice in a row. If the pool is empty, let the model generate a lightweight topic-shift line on the spot. If the model is down too, randomly pick one from a static short-sentence pool grouped by language, something like, "Hmm? What did you just say? Say it again?"
There was an earlier version of this final layer: 30% of the time it replied with a question mark, and 70% of the time it simply stayed silent. Later, when we investigated complaints about "the AI not replying," the source was exactly that 70% silence. We changed that branch completely, replacing it with short lines that the layers above could fall back to.
What If Even Error Handling Dies?
The trickiest scenario is when the instance gets killed mid-generation: the entire instance is gone, the error-handling code dies with it, and nobody is left to fall back. We solved this with leases. When a task starts, it is marked as "generating" with a lease period. After the instance comes back, if it finds a task whose lease has expired, that means the previous run died halfway through. At that point, we do not regenerate. Regenerating would mean duplicate billing and duplicate records. Instead, we send out one fallback short sentence. The user waits a bit longer, but they do get a reply.
Two Specific Pitfalls
The head-of-line blocking incident taught us a real lesson. Async callbacks were delivered in strict sequence-number order, which sounds perfectly reasonable. In practice, one callback that could never be delivered got stuck at the head of the queue and froze the entire conversation for 3.7 hours, with all later messages piling up behind it. The fix was to give up absolute ordering: once the head item has retried up to the limit, let it go, deliver the later callbacks out of order, and let the upstream side reorder them by sequence number.
The other pitfall was buried in the deduplication logic. To decide whether fallback copy was duplicated, we used longest common substring, O(n²), with no length cap. One abnormally long reply came in and blew through the single-instance 30-second CPU budget, causing the platform to forcibly reset the instance. The fix was plain: string algorithms in production need input limits.
There was a coincidence on the day the fallback went live. One minute after deployment, while running the smoke test, we happened to hit a transient error caused by an instance reset during a code update. In the past, that would have been a 500. That day, it returned a natural fallback sentence. The fallback verified itself.
Do the Math Before Cutting
We pulled a week of billing: $29.69, 517 million tokens, 63,000 requests. Spread across each user message, the full-chain cost was about $0.0008. 99.9% of the money was spent on one primary model.
Break it down another layer. A single main-chat call had 11–12k input tokens and only 36–250 output tokens. Over 95% of the cost was in input, and 80% of that input was system prompt and message history. In other words, every round we were paying to resend the same pile of nearly unchanged text.
Model providers offer prompt caching for exactly this scenario: byte-for-byte prefix matching, with cache-hit portions priced at about 1/5. If any character in the prefix changes, everything after it is invalidated. We checked our own prompt against that rule and found four cache killers.
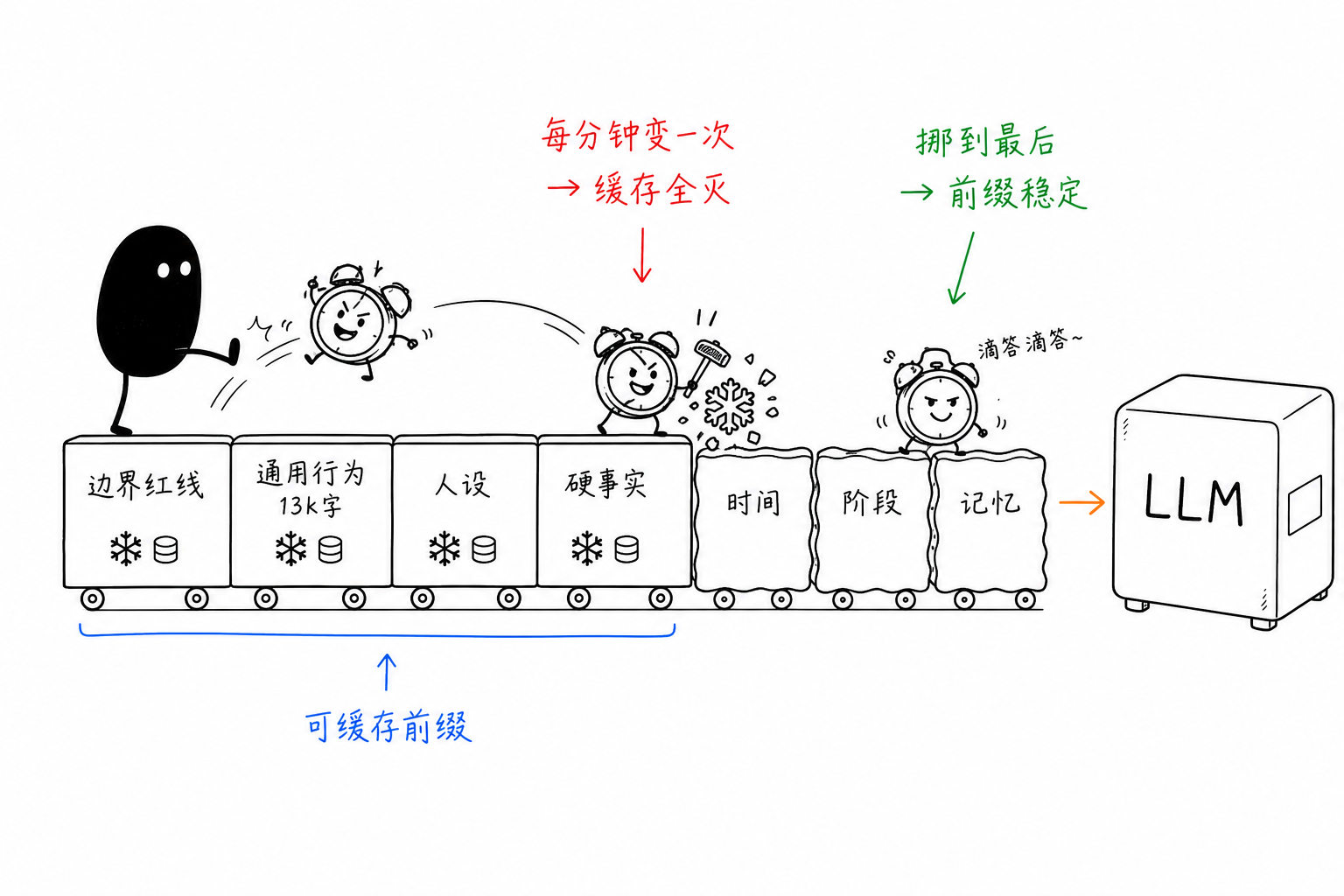
The worst one was the time block. It was precise to the minute and also included a line like “37 seconds since the last message.” It changed on every call, yet sat before thousands of tokens of static content, so one change wiped everything out. The fix was to keep time only to the hour and bucket the interval.
The relationship-stage block contained a literal turn counter, which changed every round. We changed it to bucket by tens, and it stabilized.
The third was buried deeper: context compression had no hysteresis. Once the window filled up, it deleted middle messages by salience; after that, every full window triggered another deletion, so the historical prefix of deep-chat sessions changed every round, permanently invalidating the cache for the most expensive calls. We changed it to cut a larger batch at once, then leave it untouched for a dozen-plus rounds.
Another issue was pure ordering: dynamic blocks were placed before static blocks. We moved all of them to the end of the prompt.
After those four changes, not a single word of business semantics changed. We were simply making room for the cache.
There was also a vendor-side calculation. The same model was hosted by more than a dozen providers. The cheapest one ran at 22 tokens/s, almost the slowest in the group; a 200-token reply would take 9 seconds to generate. The second tier ran at 70 tokens/s and cost only 9% more. Making users wait 9 seconds versus spending 9% more was not a hard choice: we chose speed. That decision had another hidden benefit: caches are isolated by provider. The more stable the primary provider, the fewer switches, and the higher the hit rate.
By this point, we ran into a counterintuitive conclusion: the whole thing cost $127 a month, and even cutting it in half would save only $60. Any optimization with a risk of quality regression had negative ROI. So we rejected the two big moves that looked most worthwhile: compressing the 13k-token system prompt, no; changing audit calls to sampling, also no. In the end, we shipped only the four cache changes, because they had zero impact on output. Cost reduction starts with doing the math. Once the math is done, most of the knives can stay sheathed.
In this business, the model is procured, and the persona copy comes from operations. What engineers truly deliver are the invisible details above.
 微信
微信 支付宝
支付宝
Comments
Replies are public immediately and may be moderated for policy violations.